

初识文件系统
文件系统是什么?
在已知的操作系统中,它们分别支持多种不同的文件系统。Windows 下支持 FAT、FAT32、NTFS,Linux 支持十多种的文件系统,例如:EXT2、EXT3、EXT4、NFS、NTFS等。
我们要学习文件系统,那么就需要知道文件系统是什么?维基百科上是这么解释文件系统的:
In computing, a file system or filesystem (often abbreviated to fs) controls how data is stored and retrieved. Without a file system, data placed in a storage medium would be one large body of data with no way to tell where one piece of data stops and the next begins. By separating the data into pieces and giving each piece a name, the data is easily isolated and identified. Taking its name from the way paper-based data management system is named, each group of data is called a "file". The structure and logic rules used to manage the groups of data and their names is called a "file system".
在计算机中,文件系统控制数据是如何存取的。如果没有文件系统,放置在存储介质中的数据将是一个庞大的数据主体,无法分辨一个数据从哪里停止,下一个数据又从哪里开始。通过将数据分为一块一块的,并为每一块都赋予一个名字,数据将会很容易隔离和确定。以纸质管理系统的命名方式命名,每一组数据就被称为文件。通过结构和逻辑规则来管理一组数据和名字,就被称为文件系统。
在计算机中使用文件系统,用户不必关心数据在磁盘中是如何存储,也不用关心数据被存入哪些块,只需要记住这个文件所属的目录和文件名,即可访问该文件中的数据。用户不必关心磁盘中的哪些块没有被使用,磁盘上空间的分配和释放是由操作系统完成的,只需要知道数据被写入到了哪个文件就可以了。
简而言之,文件系统是操作系统向用户提供存取数据的抽象数据结构,方便用户存储和查找数据。
文件是什么?
文件系统存取的都是文件,那么我们日常所使用的文件又是什么?
文件是一组有意义的信息/数据集合
从我们最熟悉的 Windows 操作系统出发。
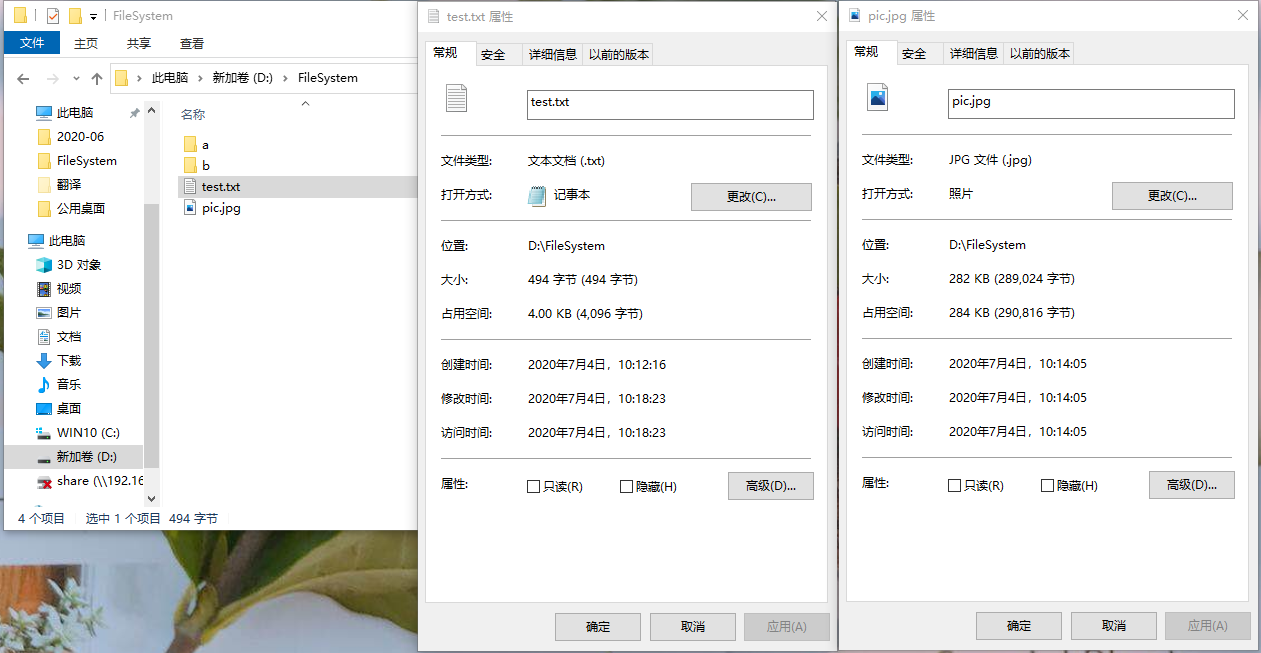
文件的属性
一个文件都有哪些属性?
- 文件名:文件名由创建文件的用户决定,主要是为了方便用户寻找文件。同一个目录下不允许出现同名文件。
- 标识符:一个系统内的各个文件都有一个唯一标识符,对用户来说毫无可读性,因此标识符只是操作系统用于区分各个文件的内部名称。
- 文件类型:指明文件的类型,比如上图中的:txt、jpg。
- 位置:文件存放的路径(用户使用)、在磁盘中的地址(操作系统使用)。
- 大小:指明文件的大小。
- 保护信息:对文件进行保护的访问控制信息。
上面列出的都是主要信息,还有其他很多的信息,如:文件所有者信息、创建时间、修改时间等等就不一一列出。
其实,上面还有一个占用空间属性,我们可以发现它都是比大小属性的数值要大。它与大小属性有什么联系呢?为什么他们的数值会不一样?哪一个才是真正的数据的大小?为什么数据的大小和数据所占用的空间不一样?
这跟文件系统如何划分存储单元有关,磁盘的存储单元是扇区(一般为 512byte),而文件系统的存储单元则是簇(一般为 4k),这些问题将会在后面进行解释。
文件逻辑结构
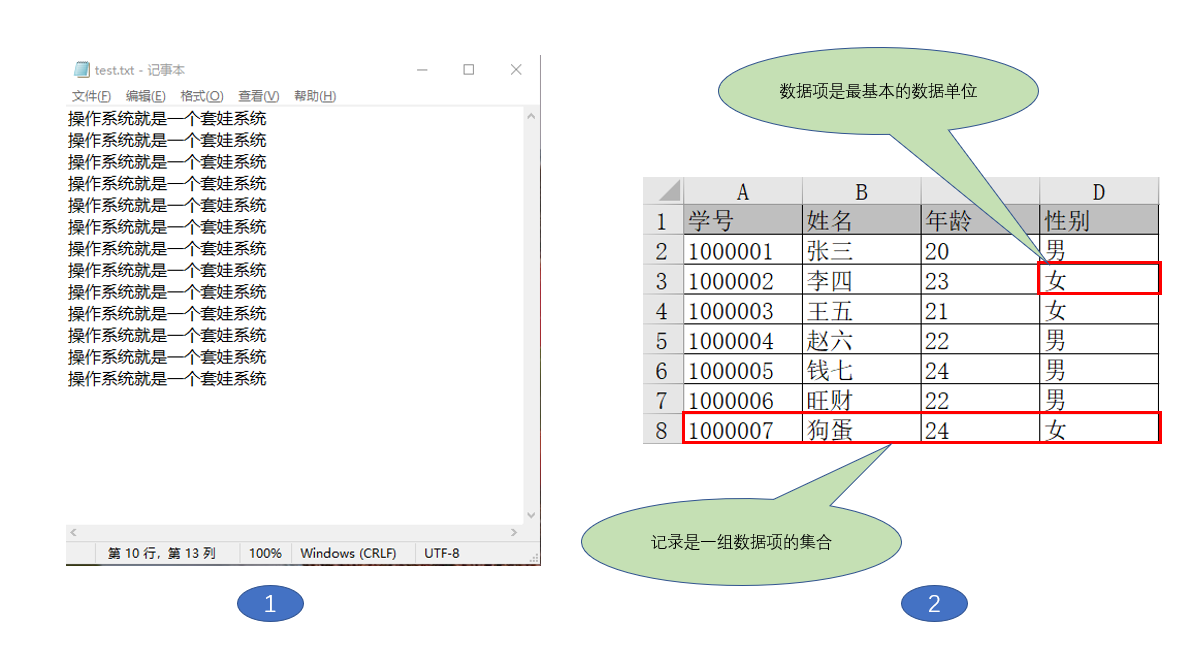
①是无结构文件(如文本文件),由一些二进制或字符流组成,又称为流式文件。②是有结构文件(如数据库表),由一组相似的记录组成,又称为记录式文件。
目录结构
我们都知道,文件是有很多的,那么文件之间是怎么组织起来的?
在文件系统中,不但存在文件,还存在目录,目录是一种特殊的文件,它不仅仅可以存储文件,还可以存储其他目录,而文件就是放在一个个的目录中。
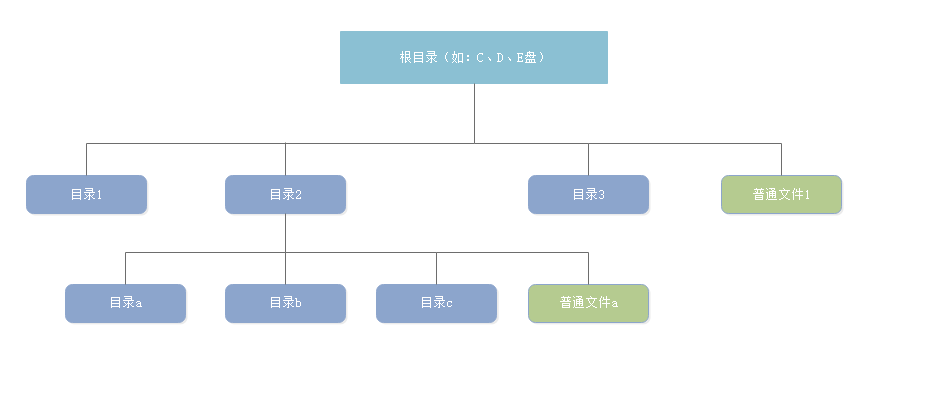
在 Windows 系统中根目录就是 C盘、D盘等,而 Linux 系统下的根目录则是 /。所谓的目录其实就是我们所熟知的文件夹,用户可以创建一层一层的目录,各层目录下可以存放其他目录,也可以存放文件,系统中的文件就是通过一层一层的目录合理有序的组织起来。
目录其实也是一种特殊的有结构文件。
系统调用
既然文件系统是提供给用户使用的,那么操作系统应该向用户提供如下功能。
- 创建文件:
create系统调用。 - 删除文件:
delete系统调用。 - 读文件:
read系统调用,将文件数据从磁盘读入内存中。 - 写文件:
write系统调用,将文件数据从内存写回磁盘中。 - 打开文件:
open系统调用,读/写文件之前,需要”打开文件“。 - 关闭文件:
close,读/写文件之后,需要”关闭文件“。
这些最基本的功能,可以组合起来,形成一些复杂的功能,比如复制文件,可以创建一个新文件,然后将其他文件内存读入内存,然后将内存中的数据写入新文件。
文件的逻辑结构
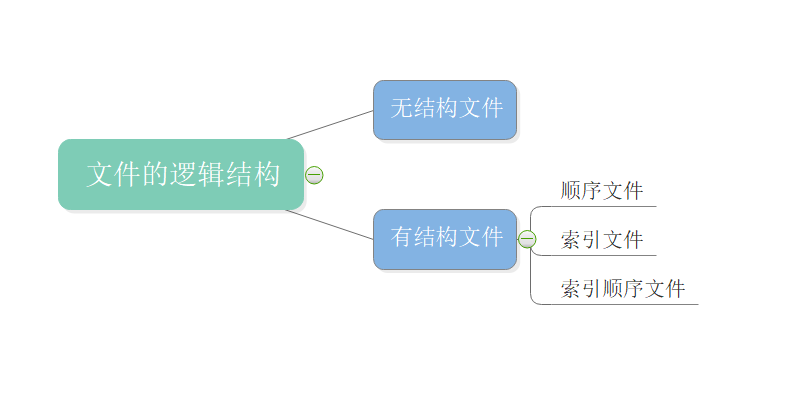
文件的逻辑结构是指在用户看起来文件的内部是如何组织起来的。逻辑结构可以用不同的物理结构来实现,如:线性表就是一种逻辑结构,它可以使用数组或者链表来实现,数组在逻辑上和物理上都是连续的,而链表是在逻辑上连续的,在物理上是离散的。因此,数组可以实现随机访问,而链表无法实现随机访问。
我们在上一个章节中知道文件的逻辑结构分为:无结构文件和有结构文件。
无结构文件:文件内部是由一系列连续的二进制流或者字符流组成,常见的有,文本文档。
有结构文件:我们重点要讲的就是有结构文件。它是由一组相似的记录组成的,每条记录项又由若干个数据项组成,常见的有,数据库表。一般来说,每条记录有一个数据项作为关键字。根据各条记录的长度是否相等,又可分为定长记录和可变长记录(类似于 MySQL 中的 char 和 varchar,只不过这里指整条记录,而不是某一个数据项)。
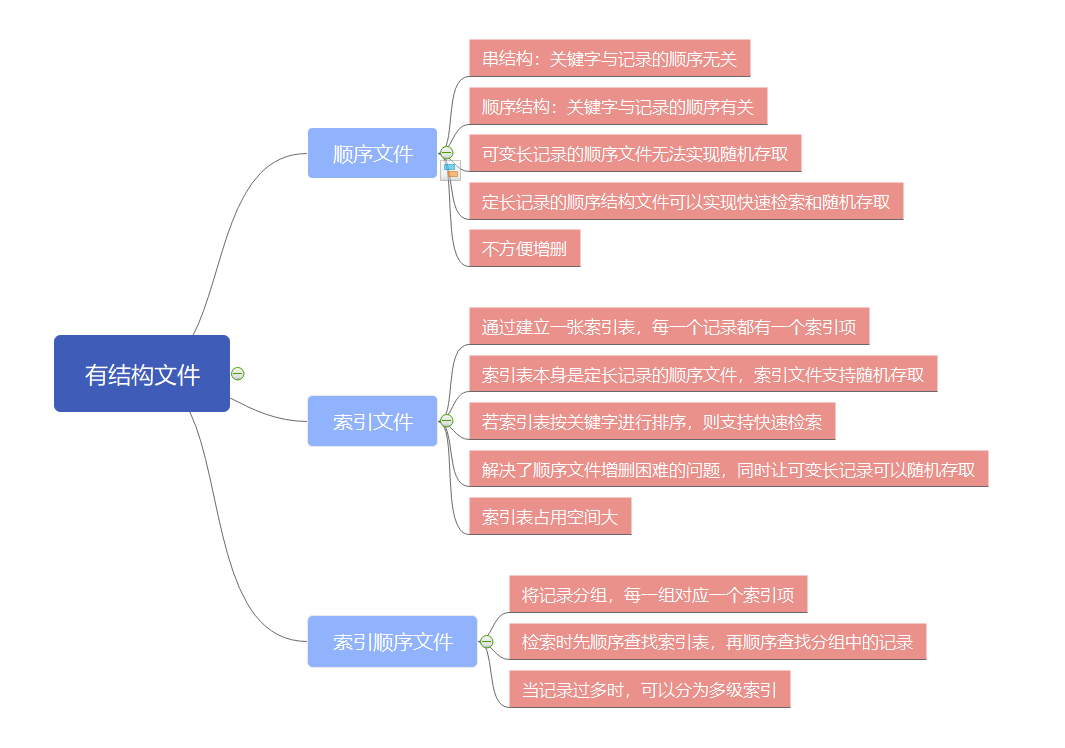
无结构文件
UNIX 和 Windows 都采用无结构文件,因为事实上操作系统并不关心文件的内容是什么,操作系统所见到的就是字节,文件所表示的内容将由用户程序进行解释。把文件看出字节序列为操作系统提供了很大的灵活性,用户程序可以往文件中加入任何内容,并以任意方便的形式命名。操作系统不提供任何帮助,也不会构成障碍。
有结构文件
顺序文件
文件中的记录一个接一个地顺序排列(逻辑上),记录可以是定长的或可变长的。各个记录在物理上可以顺序存储或链式存储。
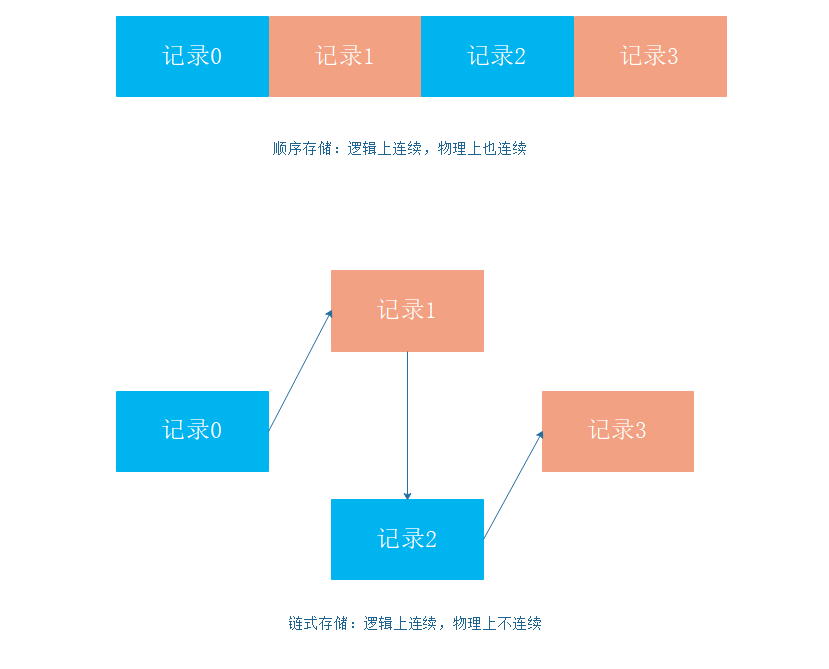
顺序文件中的记录又是如何排列的呢?因为不同的排列也会影响到查找的效率。在顺序文件中,记录的顺序分为两种形式:
- 串结构:记录之间的顺序与关键字无关,通常是按照记录存入的时间决定记录的顺序。
- 顺序结构:记录之间的顺序按关键字顺序排列。
假设已经知道了文件的起始地址,也就是第一个记录存放的地址。我们现在来思考两个问题:
- 能否快速找到第 i 个记录对应的地址,即能否实现随机存取?
- 能够快速找到某个关键字对应的记录存放的位置?
首先,如果采用链式存储来实现顺序文件的话,那么上面的两个问题必然是无法实现的。因为链式存储的性质就决定了它无法完成此功能。那么我们就要来考虑一下顺序存储是否能够满足。
在使用顺序存储的时候,我们要知道记录有两种:定长记录和可变长记录。下图是使用顺序存储记录的结构。
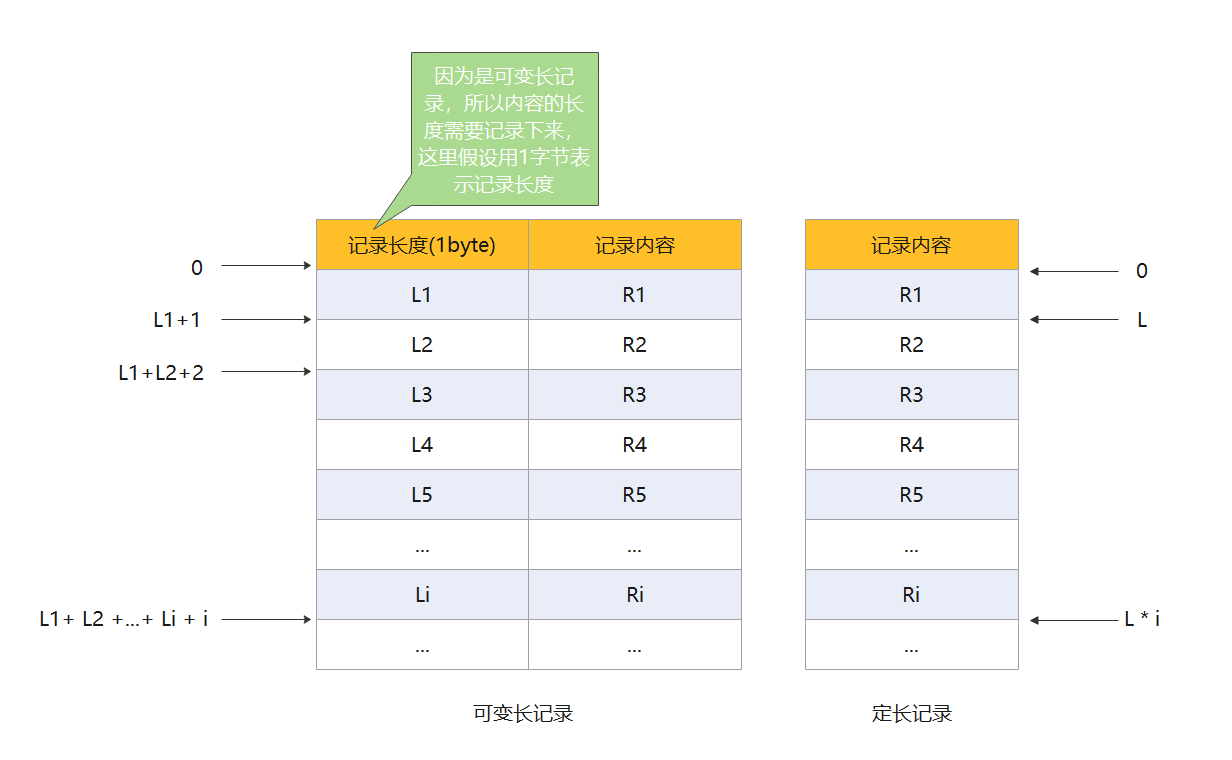
根据上面的图可以得出结论:可变长记录因为记录长度的不确定性,是无法实现随机存取的。而定长记录若物理上是连续的,那么是可以实现随机存储,如果能够保证记录的顺序结构,那么还可以实现快速检索。

索引文件
对于可变长记录,在查找第 i 个记录时,必须先查找前 i - 1 个记录。但是在很多情况下,又必须使用可变长记录。所以,就出现了新的文件结构——索引文件。
它通过建立一个索引表来加快文件检索速度,每一条记录都是一个索引项。
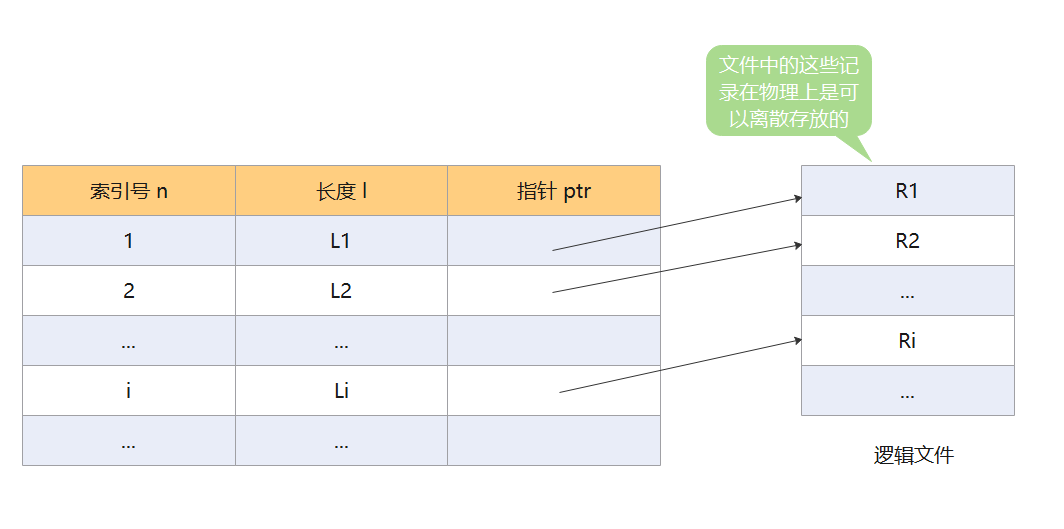
索引表本身是一个定长记录的顺序文件,因此可以快速找到第 i 个记录对应的索引项。可将关键字作为索引号内容,若按关键字顺序排列,则还可以支持按照关键字进行二分查找。由于索引文件又很快的检索速度,因此主要用于对信息处理的及时性要求很高的场合。
另外,还可以使用多个不同的数据项建立多个索引表。如果学习过数据库的话,很容易就可以想到这就是数据库中常用的索引。可以根据不同的字段为同一张表建立不同的索引用于快速查找数据。
索引顺序文件
我们来看看索引文件有什么缺点。在索引文件中,文件中每一条记录都存在一个索引项与其对应,如果文件记录的内容很小,就会导致索引表所占用的空间比文件内容本身还多,磁盘的利用率就会很低。所以,我们应该想办法减少索引表中的索引项。
由上面的问题,由此出现了一种新的文件存储结构——索引顺序文件。顾名思义,这是索引文件和顺序文件思想的结合。
在索引顺序文件中,同样会为文件建立一个索引表,但是与索引文件不同的是,它不会为每一个记录都创建一个索引项,而是为一组记录创建一个索引项。
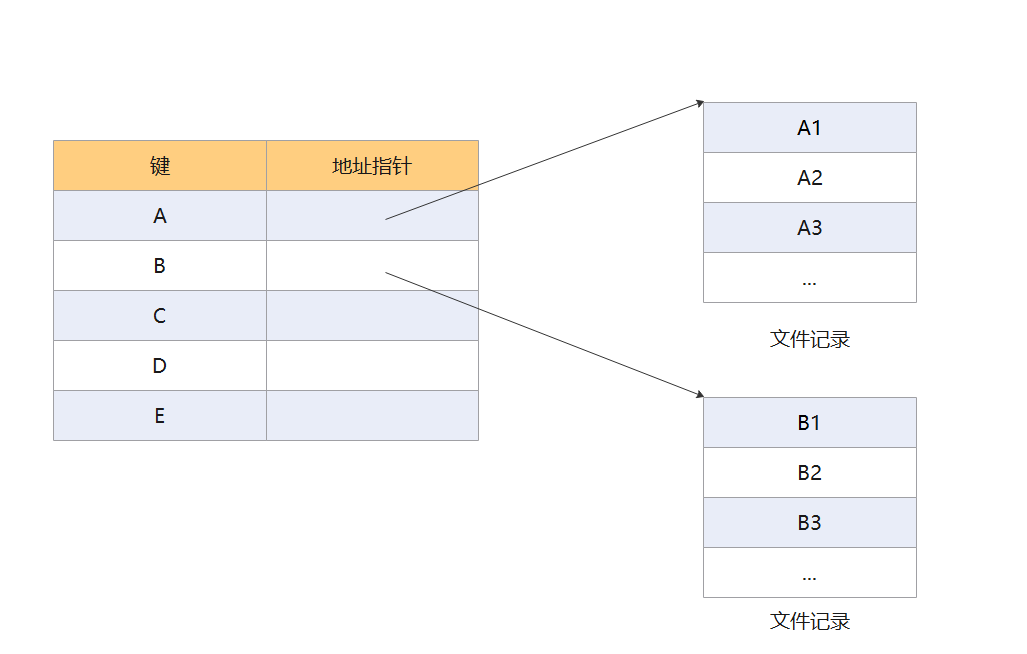
索引表中的数据项不需要按照关键字进行排序,这样有利于插入新的数据项。索引表中每一个数据项都指向一个分组,每一个分组都是一个顺序文件,分组内的记录也不需要按照关键字排序。
索引顺序文件确实可以让索引表占用的空间变小,但是可以看到,索引表和文件记录都是不排序的,那么它对于不定长记录的检索速度真的会快吗?
假设一个顺序文件中有 10000 条记录,根据关键字检索文件,只能从头开始检索(这里的记录是不定长记录),那么平均检索次数为 5000 次。
若采用索引顺序文件,将 10000 条分为 100 组,每一组就有 100 条记录。我们根据关键字来检索文件,首先在索引表中检索,因为索引表是无序的,所以只能从第一条索引项开始查找,这里平均需要检索 50 次,然后根据得出的地址指针,可以得到需要检索的分组,因为每一个分组都假设为 100 条记录,并且这 100 条是无序的,所以只能从第一条开始查找,平均查找次数为 50 次。那么总共要查找的次数就是 50 + 50 = 100。所以,索引顺序文件相对于顺序文件来说,检索速度还是相对较快的。
多级索引顺序文件
上面说到,在 10000 条记录的情况下,索引顺序文件的检索速度还是比较快的。但是,如果有 10^5^、10^6^ ,甚至更多的记录,检索速度依然会变得很慢。此时不能使用单一的索引表,可以根据索引表再建立一个索引表。之前都是为记录建立索引表,而现在是为索引表中的索引项建立一个索引表。
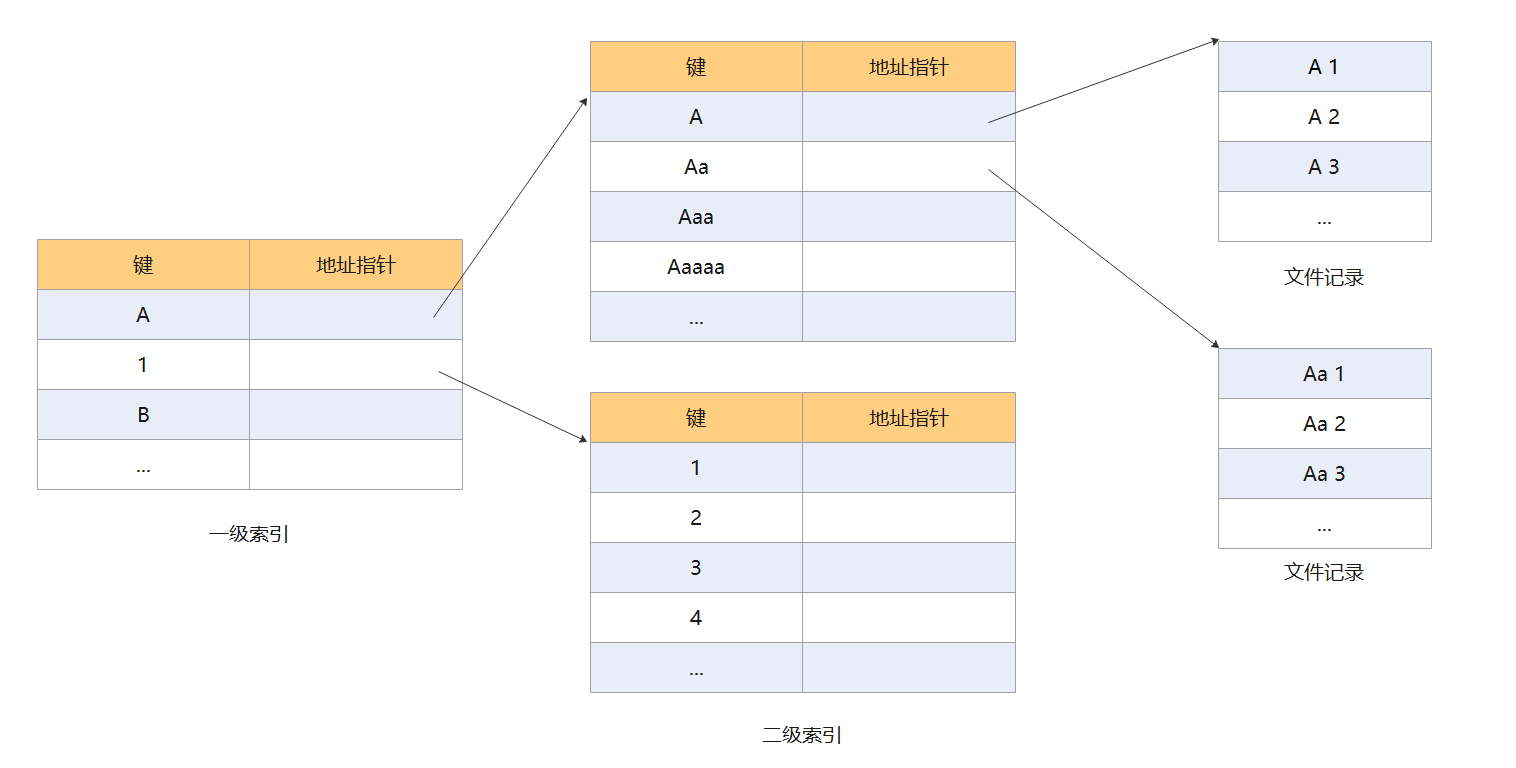
由于创建了多级索引,所以检索应该从最顶级的索引开始,然后一层一层往低级索引查找,组后定位到记录分组,在分组中进行查找对应的记录。
其实,这就是一个 B+ 树的雏形,只不过里面的项是无序的,而 B+ 树中是有序的。如果你学过数据库中索引的原理,那么理解这个文件结构应该非常的容易。相反,如果你理解了这个文件结构再去学习数据库的索引结构,也是非常简单的。
文件的物理结构
在操作系统的辅助之下,磁盘中的数据在计算机中都会呈现为易读的形式,并且我们不需要关心数据到底是如何存放在磁盘中,存放在磁盘的哪个地方等等问题,这些全部都是由操作系统完成的。
那么,文件数据在磁盘中究竟是怎么样的呢?我们来一探究竟!
文件块
磁盘中的存储单元会被划分为一个个的“块”,也被称为扇区,扇区的大小一般都为 512byte。这说明即使一块数据不足 512byte,那么它也要占用 512byte 的磁盘空间。(磁盘的组成结构后面将会详细介绍)
而几乎所有的文件系统都会把文件分割成固定大小的块来存储,通常一个块的大小为 4K。如果磁盘中的扇区为 512byte,而文件系统的块大小为 4K,那么文件系统的存储单元就为 8 个扇区。这也是前面提到的一个问题,文件大小和占用空间之间有什么区别?文件大小是文件实际的大小,而占用空间则是因为即使它的实际大小没有达到那么大,但是这部分空间实际也被占用,其他文件数据无法使用这部分的空间。所以我们写入 1byte 的数据到文本中,但是它占用的空间也会是 4K。
这里要注意在 Windows 下的 NTFS 文件系统中,如果一开始文件数据小于 1K,那么则不会分配磁盘块来存储,而是存在一个文件表中。但是一旦文件数据大于 1K,那么不管以后文件的大小,都会分配以 4K 为单位的磁盘空间来存储。
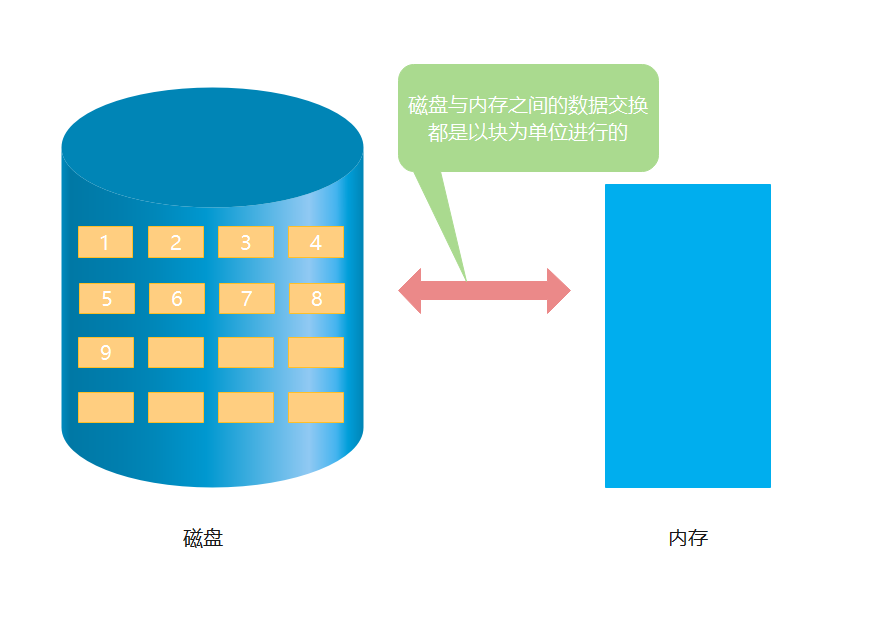
与内存管理一样,为了方便对磁盘的管理,文件的逻辑地址也被分为一个个的文件块。于是文件的逻辑地址就是(逻辑块号,块内地址)。用户通过逻辑地址来操作文件,操作系统负责完成逻辑地址与物理地址的映射。
文件分配方式
不同的文件系统为文件分配磁盘空间会有不同的方式,这些方式各自都有优点和缺点。
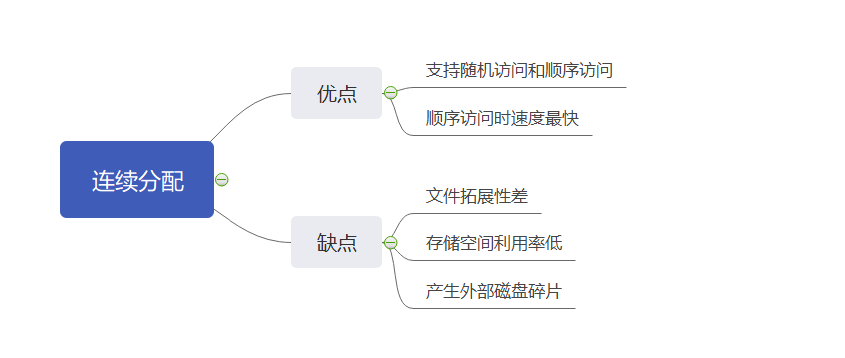
连续分配
连续分配要求每个文件在磁盘上占有一组连续的块,该分配方式较为简单。
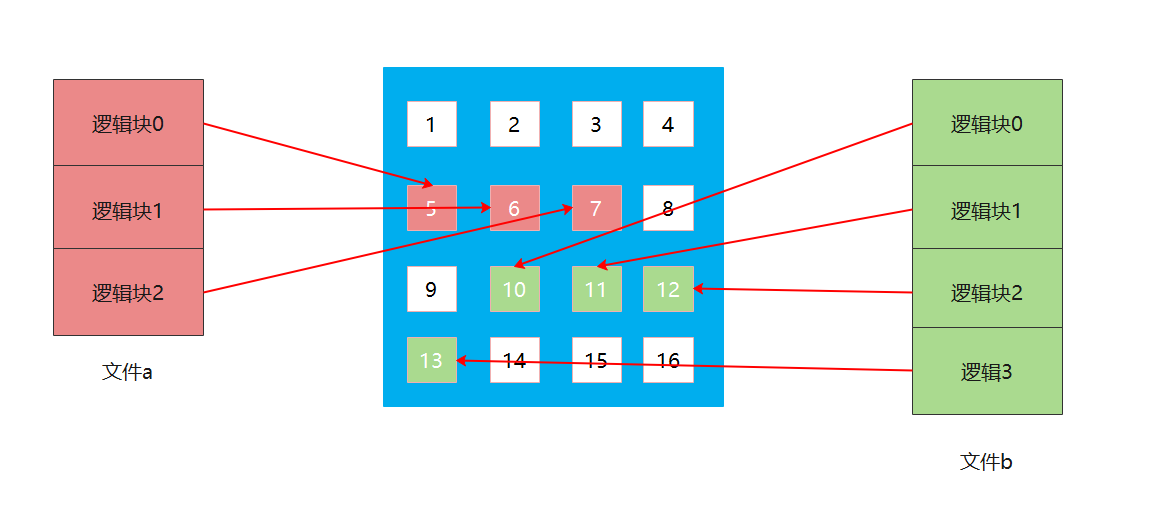
通过上图可以看到,文件的逻辑块号的顺序是与物理块号相同的,这样就可以实现随机存取了,只要知道了第一个逻辑块的物理地址,那么就可以快速访问到其他逻辑块的物理地址。那么操作系统如何完成逻辑块与物理块之间的映射呢?实际上,文件都是存放在目录下的,而目录是一种有结构文件,所以在文件目录的记录中会存放目录下所有文件的信息,每一个文件或者目录都是一个记录。而这些信息就包括文件的起始块号和占有块号的数量。
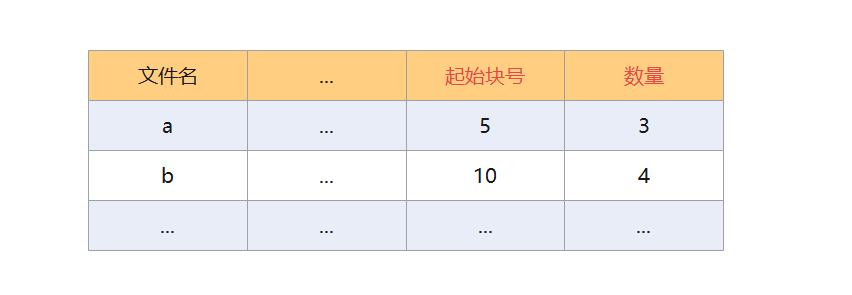
那么操作系统如何完成逻辑块与物理块之间的映射呢?(逻辑块号,块内地址)-> (物理块号,块内地址),只需要知道逻辑块号对应的物理块号即可,块内地址不变。
用户访问一个文件的内容,操作系统通过文件的标识符找到目录项 FCB,物理块号 = 起始块号 + 逻辑块号。当然,还需要检查逻辑块号是否合法,是否超过长度等。因为可以根据逻辑块号直接算出物理块号,所以连续分配支持顺序访问和随机访问。
因为读/写文件是需要移动磁头的,如果访问两个相隔很远的磁盘块,移动磁头的时间就会变长。使用连续分配来作为文件的分配方式,会使文件的磁盘块相邻,所以文件的读/写速度最快。
但是,连续分配的缺点也很明显,文件的拓展性差,外部碎片多,磁盘利用率低,如下图所示:
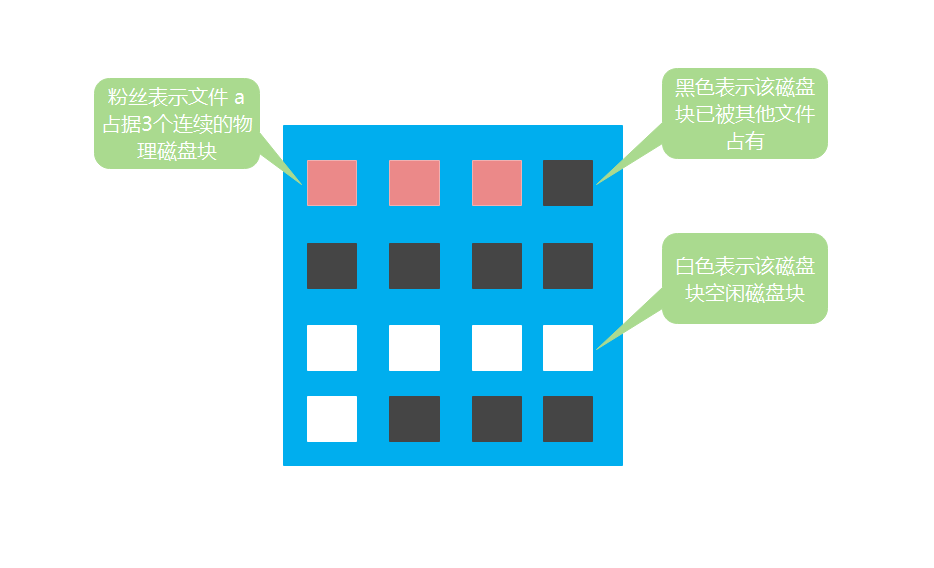
如果此时文件 a 需要申请一个新的磁盘块,但是目前文件 a 所占的磁盘块后面没有空闲的可用磁盘块。那么只能重新找一个符合文件 a 要求的连续磁盘块,将文件 a 的内容复制过去。从图中可以看出,只有下方的白色区域符合条件,所以此时磁盘的情况如下图所示:
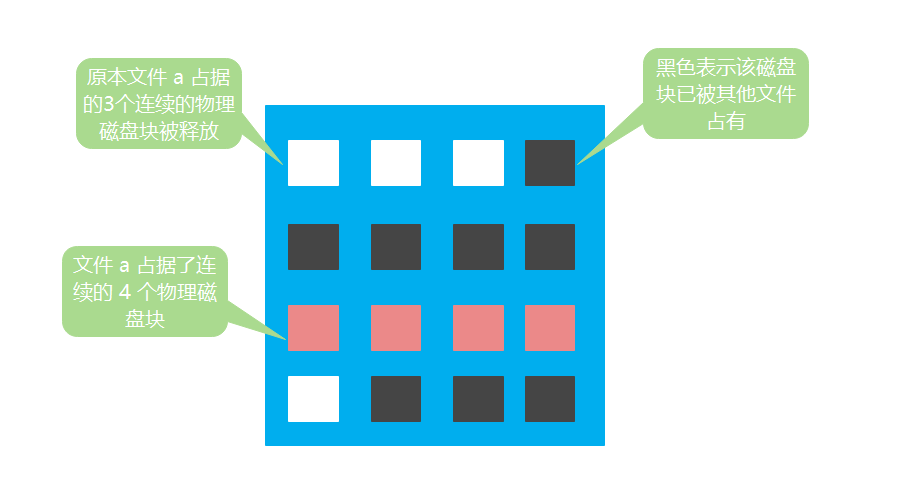
此时,存在两块空闲区域,一块有 3 个连续空闲块,一块有 1 个空闲块。假设现在又有一个文件需要申请 4 个磁盘块,虽然磁盘有容纳该文件的空间,但是没有连续的 4 个磁盘块,所以文件系统将无法完成分配,需要将磁盘中的内容进行紧凑整理之后才能分配。紧凑整理需要耗费较长的时间,代价较高。
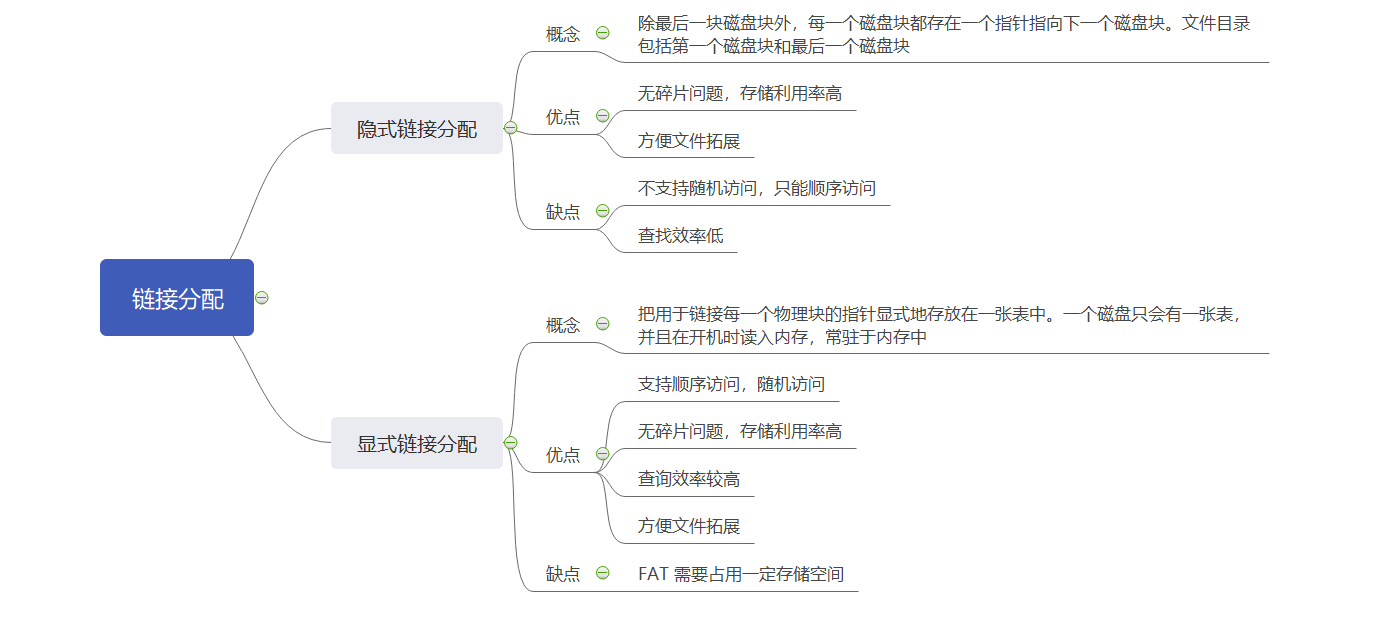
链式分配
链式分配采取离散分配的方式,可以为文件分配离散的磁盘块。它有两种分配方式:显示链接和隐式链接。
隐式链接
隐式链接是只目录项中只会记录文件所占磁盘块中的第一块的地址和最后一块磁盘块的地址,然后通过在每一个磁盘块中存放一个指向下一磁盘块的指针,从而可以根据指针找到下一块磁盘块。如果需要分配新的磁盘块,则使用最后一块磁盘块中的指针指向新的磁盘块,然后修改新的磁盘块为最后的磁盘块。
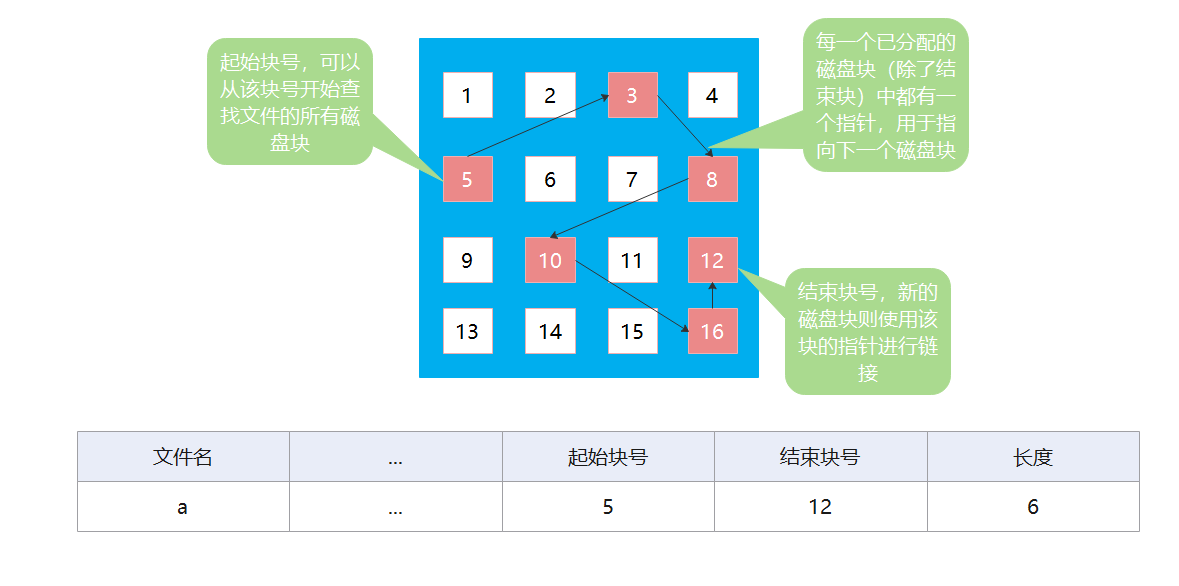
我们来思考一个问题,采用隐式链接如何将实现逻辑块号转换为物理块号呢?
用户给出需要访问的逻辑块号 i,操作系统需要找到所需访问文件的目录项 FCB。从目录项中可以知道文件的起始块号,然后将逻辑块号 0 的数据读入内存,由此知道 1 号逻辑块的物理块号,然后再读入 1 号逻辑块的数据进内存,此次类推,最终可以找到用户所需访问的逻辑块号 i。访问逻辑块号 i,总共需要 i + 1 次磁盘 I/O 操作。
得出结论:隐式链接分配只能顺序访问,不支持随机访问,查找效率低。
我们来思考另外一个问题,采用隐式链接是否方便文件拓展?
我们知道目录项中存有结束块号的物理地址,所以我们如果要拓展文件,只需要将新分配的磁盘块挂载到结束块号的后面即可,修改结束块号的指针指向新分配的磁盘块,然后修改目录项。
得出结论:隐式链接分配很方便文件拓展。所有空闲磁盘块都可以被利用到,无碎片问题,存储利用率高。
显式链接
显示链接是把用于链接各个物理块的指针显式地存放在一张表中,该表称为文件分配表(FAT,File Allocation Table)。
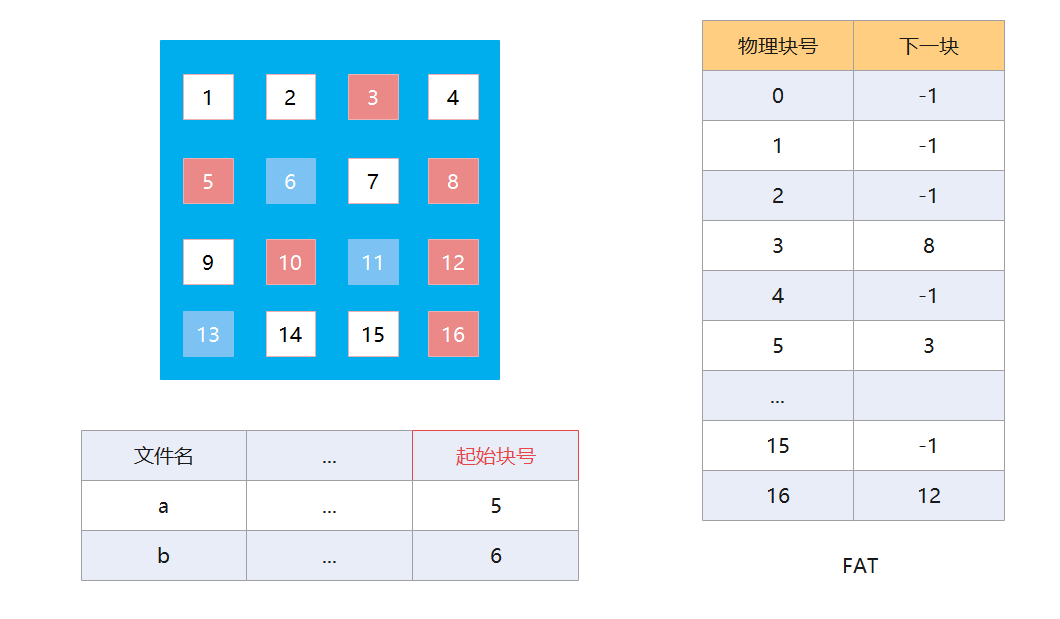
在记录项中只会机会每个文件的起始块号,然后根据起始块号去 FAT 中查找对应的磁盘块。每一个磁盘只会存在一个 FAT,并且在开机的时候会将整个 FAT 加载进内存中,并常驻内存。FAT 的各个表项在物理上是连续存储的,且每个表项的长度相同,所以物理块号是隐含的,可以通过计算得到,而不需要记录。
我们通过上图可以看到,文件 a 从磁盘块号 5 开始存储,然后就可以在 FAT 中通过找到物理块号为 5 的表项,从而可以得到下一个物理块号,以此类推,可以得到整个文件的所有占有的物理块号。
采用显式链接如何实现将逻辑块号转换为物理块号呢?
用户首先给出需要访问的逻辑块号 i,操作系统找到该文件对应的 FCB。从 FCB 中可以得到起始块号,如果 i > 0,则在 FAT 中往后找到 i 号逻辑块对应的物理块号。逻辑块号与物理块号之间的转换并不需要磁盘 I/O 操作,因为 FAT 是在内存中的。
得出结论:显式链接分配支持顺序访问和随机访问(只要给出需要访问的逻辑块号 i 即可,不需要依次访问之前的 0 ~ i - 1号逻辑块,直接从 FAT 中即可找到)。由于块号转换的过程不需要访问磁盘,所以相比于隐式连接来说,访问速度会快很多。
并且显式分配也不会产生磁盘碎片,存储利用率高,文件拓展性好。
索引分配
索引分配允许文件离散地分配在各个磁盘块中,系统会为每一个文件建立一个索引表,索引表中记录了文件中每个逻辑块对应的物理块。索引表存放的磁盘块叫做==索引块==,文件数据存放的磁盘块叫做==数据块==。
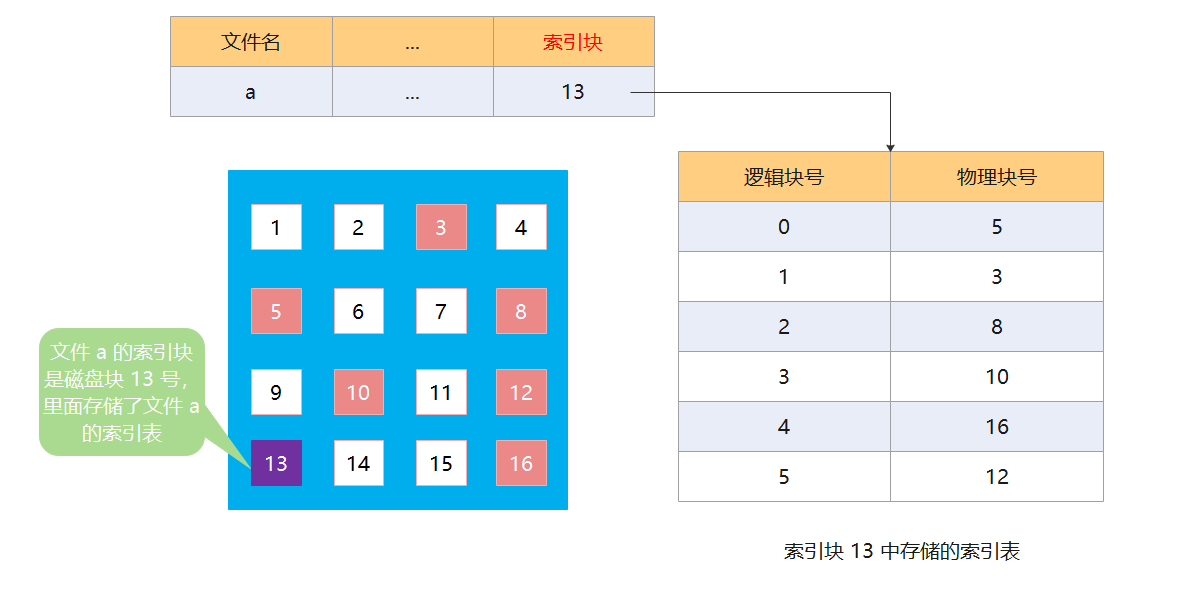
这里要与显式链接区分清楚,显式链接中的 FAT 是每个磁盘只会存在一张,而索引分配中的索引表是每个文件都会存在一张。
并且因为逻辑块号的长度(比如 4byte)是固定的,那么逻辑块号可以通过计算得出,而不需要显式的记录。比如,第一个 4byte 则表示第一个逻辑块号对应的物理块号,第二个 4byte 表示第二个逻辑块号对应的物理块号,以此类推。
还会回到最初的问题,采用索引链接如何实现将逻辑块号转换为物理块号呢?
首先,用户给出需要访问的逻辑块号 i,操作系统需要找出所需访问的文件的目录项(FCB),在 FCB 中可以找到索引块的物理块号,通过该物理块号,可以找到索引表,将索引表读入内存,并在索引表中查找需要的逻辑块 i 对应的物理块即可。
得出结论:支持顺序访问和随机访问,文件拓展实现容易(只需要给文件分配一个空闲块,并增加一个索引项即可)。但是索引表需要占用一定空间。
现在我们需要考虑另外一个问题,假设一个磁盘块的大小为 512byte,一个索引项为 4byte,那么一个磁盘块只能记录 128 个索引项,但是如果一个文件的大小超过了 128 个磁盘块,那么索引项使用一个磁盘块是无法存放的,此时应该怎么办呢?
我们能想到的就是,既然一个磁盘块存放不下,那么就使用两块。对的,这种想法是没错的,但是我们要考虑的是在使用多个磁盘块的时候,如果将这多个磁盘块关联起来,同时还能不降低查询效率?
这里又出现了三种方案来解决:链接方案、多层索引、混合索引。
链接方案
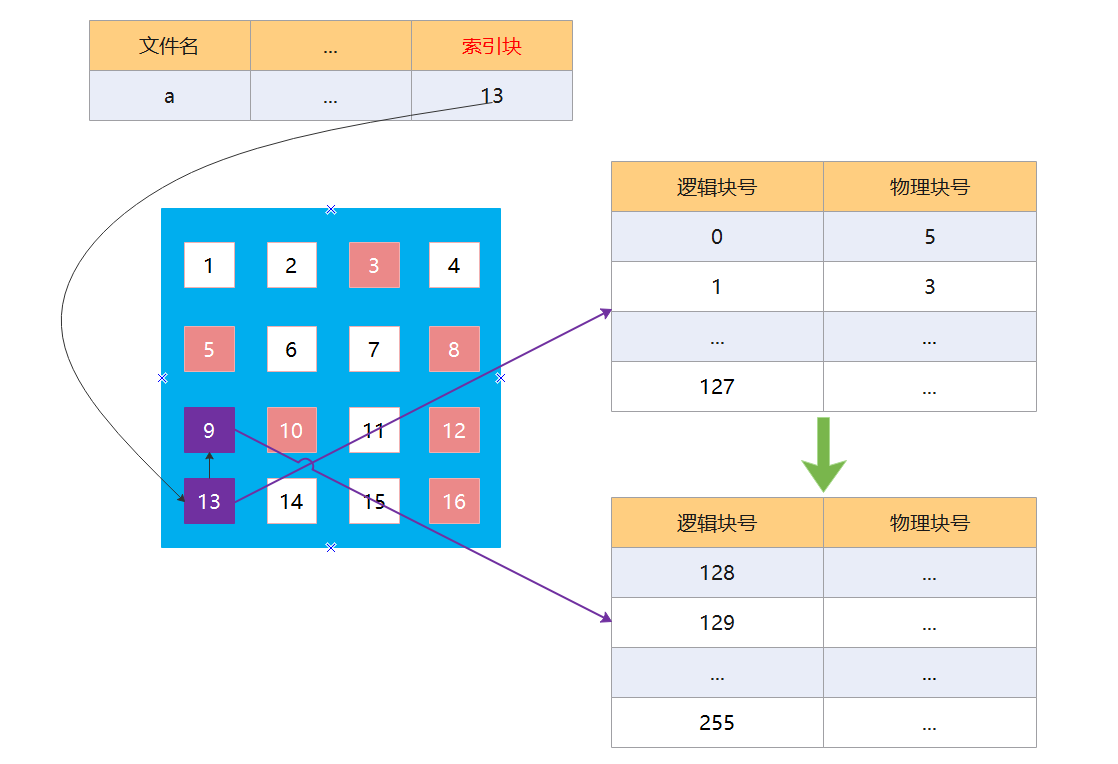
链接方案有点类似于隐式链接,都是在磁盘块中存储一个指向下一个磁盘块的指针,通过这个指针可以找到下一个索引块。
假设一个磁盘块的大小为 512byte,一个索引项为 4byte,那么一个磁盘块只能记录 128 个索引项。若一个文件的大小为 128 * 128KB = 16384KB = 16M,那么该文件就占用 128 * 128 * 2 个磁盘块,那么也对应需要 128 * 128 * 2 个索引项,那么就需要 64 个索引块来存储,这些索引块使用链接方案关连起来。
若想要访问到最后一个逻辑块,那么就需要找到最后一个索引块,而各个索引块是使用指针链接起来的,所以必须访问到前 63 个索引块才能够获取得到最后一个逻辑块的数据。
这种方式最大的问题就是访问效率慢,那么有什么方式可以改进呢?
多层索引
我们知道使用链接方案来存储索引块时,访问索引块 i 时,需要先访问 i - 1 个索引块,这就导致了访问效率的低下。
既然使用链接方案慢,那么安装我们之前的,是不是可以考虑使用索引呢?
建立多层索引,使第一层的索引块指向第二层的索引块,还可以根据文件的大小建立第三层、第四次索引块。
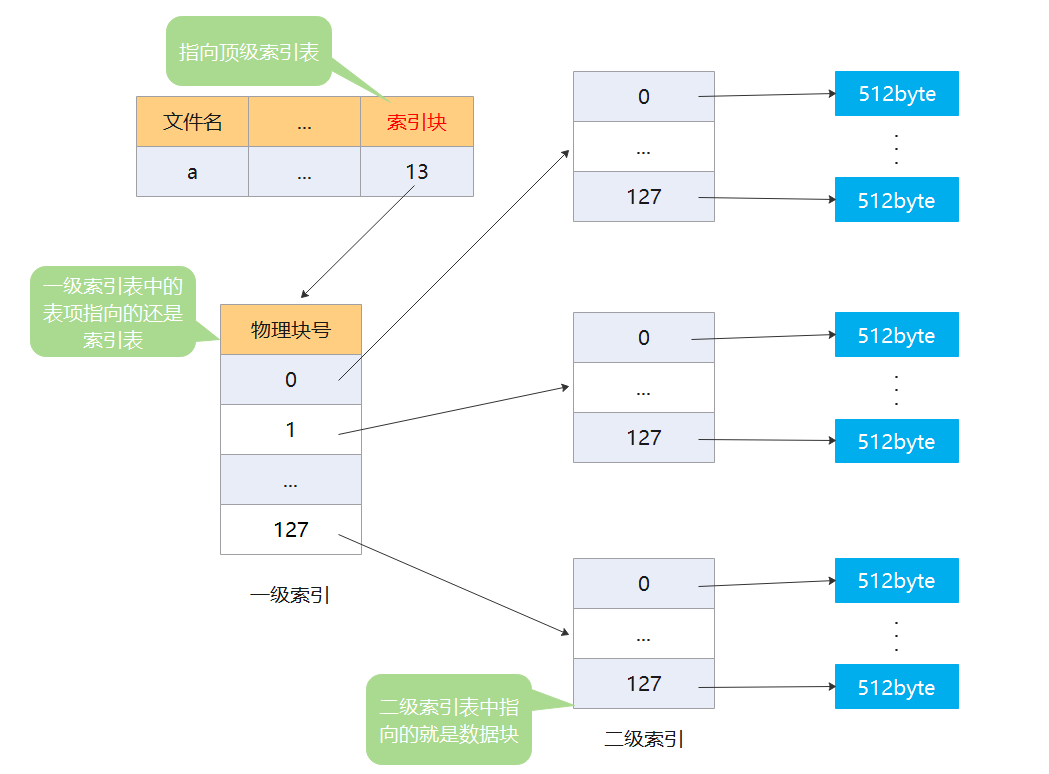
我们依然使用上面的那个例子,假设一个磁盘块的大小为 512byte,一个索引项为 4byte,那么一个磁盘块只能记录 128 个索引项。若一个文件的大小为 128 * 128KB = 16384KB = 16M,该文件就占用 128 * 128 * 2 个磁盘块,对应需要 128 * 128 * 2 个索引项,需要 64 个索引块来存储。我们使用二层索引来存储这个文件。
假设我们需要查找的逻辑号为 1002 这个磁盘块,首先我们需要找到一级索引块,也就是先要找到文件的目录项,然后根据目录项中记录的索引块地址,将一级索引块读入到内存中,我们可以根据计算得出,要访问的要二级索引块是 1002 / 128 = 7,要访问二级索引块中的索引项是 1002 % 128 = 106,所以,最终要访问的物理块在(7,106),一级索引表中的第 7 个索引项,二级索引表中的第 106 个索引项指向的物理块。这里一共发生了 3 次磁盘 I/O 操作,分别是读入文件目录项、读入一级索引表、读入二级索引表。
混合索引
混合索引是多种索引分配方式的结合。一个文件的顶级索引中即包含直接索引(直接指向数据块),还包含一级间接索引,还包含二级间接索引。
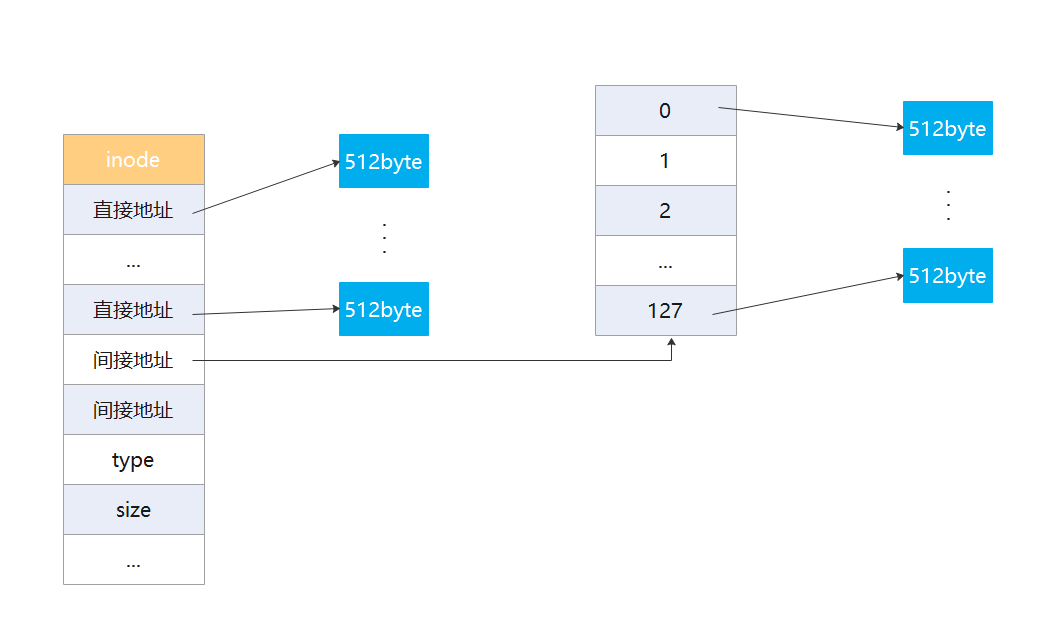
因为顶级索引表中包含了有一部分的磁盘块地址,对于小文件来说,访问磁盘所需的 I/O 操作会更少。

总结
文件系统是操作系统中的一大不可或缺模块,为用户屏蔽了磁盘的细节,提供给用户操作数据的便利。
