


阿里巴巴集团前端委员会主席 @圆心 对前端未来期许有四点:搭建服务, Serverless,智能化,IDE。仔细想想,一个「可视化搭建系统」的想象空间,正能完美命中这些方面。前端的边界在哪里,对于业务的价值又在哪里,我们不妨静下来,一起从「可视化搭建系统」的角度来思考。
—— 有人说前端「可视化搭建系统」说到底只是重复造轮子产生的玩具;有人说前端「可视化搭建系统」本质是组件枚举,毫无意义。片面的认知必有其产生道理,但我们不妨从更高的角度出发,并真切落地实践,也许你会发现:作为 FEer,我们能做的事情也许更多。
页面搭建技术流派概览和彩蛋放送
据我观察“几乎每一个前端团队,都会有一个页面搭建系统”。**页面搭建技术是一个老生常谈的话题,可这个话题伴随着前端技术的发展,历久弥新。**究其原因,包括但不限于:
- 运营活动页面对于产品业务至关重要,是吸引流量、提高留存的关键手段
- 高频且重复度较高的活动页面开发,对于前端意味着大量的时间和人力成本消耗
在此背景下,快速页面搭建技术就显得尤为重要。
由于每个产品业务的特点、运营需求和设计规范不尽相同,因此页面搭建平台就出现了“百花齐放,百家争鸣”的局面。我们在“闭门造车”的同时,博览众家之长,对比归纳,持续优化。为此,我们分析了社区上几乎所有开源产品和方案,包括但不限于:
- 百度 H5
- iH5
- 转转魔方平台
- 百度外卖页面配置平台:Blocks
- 携程乐高系统
- 人人贷活动运营平台
- 新版微信编辑器
- 鲁班H5
- 阿里云凤蝶
- MAKA
- 码良平台
- grapes
- 可视化布局 bootcss
- 民间方案:pipeline-editor
- 一个国外的民间方案:vvvebjs
相关技术分析文章:
- 页面可视化搭建工具前生今世
- 页面可视化搭建工具技术要点
- QQ会员活动运营平台演变和技术实践——高效活动运营
- 积木系统,将运营系统做到极致
- 活动运营自动化平台实践
- 可视化搭建前端工程 - 阿里飞冰了解一下
- 飞冰对于活动引擎的可借鉴之处
- 前端工程实践之可视化搭建系统
- 如何设计高扩展的在线网页制作平台
- 鲁班H5作者:@小小鲁班
- 厌倦了写活动页?快来撸一个页面生成器吧!
其特点和技术方向可以各有特点,但总体可以归纳为以下图示:
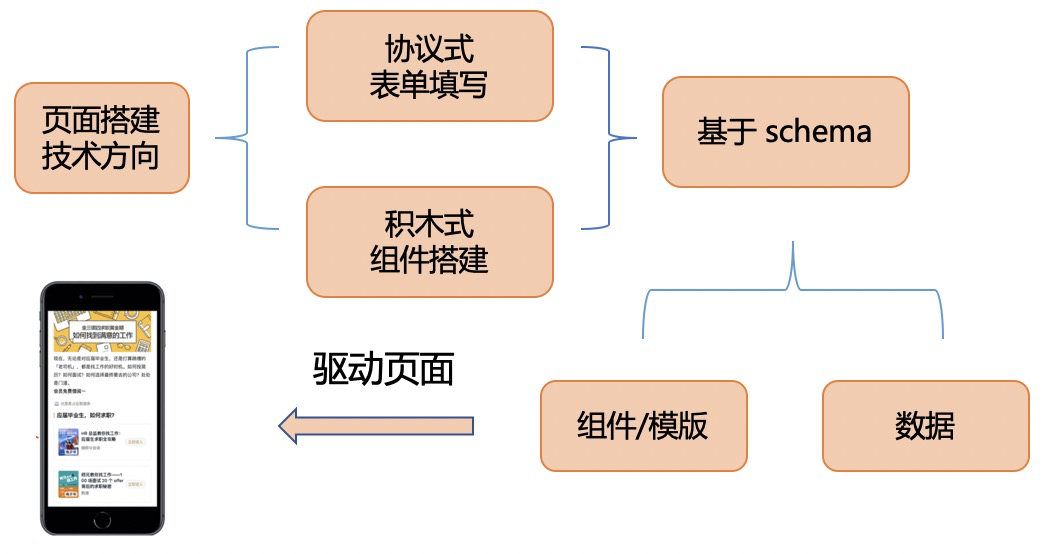
按照目标受众,可区分:

我们也从海量优秀方案中总结出解决这一类运营需求的**通用手段:将复杂页面的搭建抽象成结构化数据,由结构数据驱动组件/模版的拼装。**简单的这样一句话很好理解,按照这样的想法也能构建出一个可用的平台,但能否更进一步,想在技术和业务上突破瓶颈,还需要打通更多环节:
- 结构化数据如何设计才能兼顾优雅和高性能,且天然支持活动编辑时的“时光旅行 Redo/Undo”功能
- 如何平衡页面的自由发挥度和规范统一度
- 如何突破原始模版引擎,借力框架(React、Vue 等)组件化思想,并做到 framework free
- 如何优雅实现专题模版功能,一键导入功能以及插拔式编辑
- 如何贴合自身业务特点,平衡实用性、适用性和可扩展性
- 如何不断持续迭代,以适应新的需求发展
- 如何借助社区的力量,做大做强
- 如何最大化发挥可配置,如何最大化方便接入方扩展
- 如何避免组件枚举堆积的混乱
业界已有方案中,有的较好地解决了这些关键点中一个或多个问题,有的更像是一个练手的玩具。请读者继续阅读,接下来我将介绍「结合编辑器技术的页面搭建平台」思路,整体如下图:
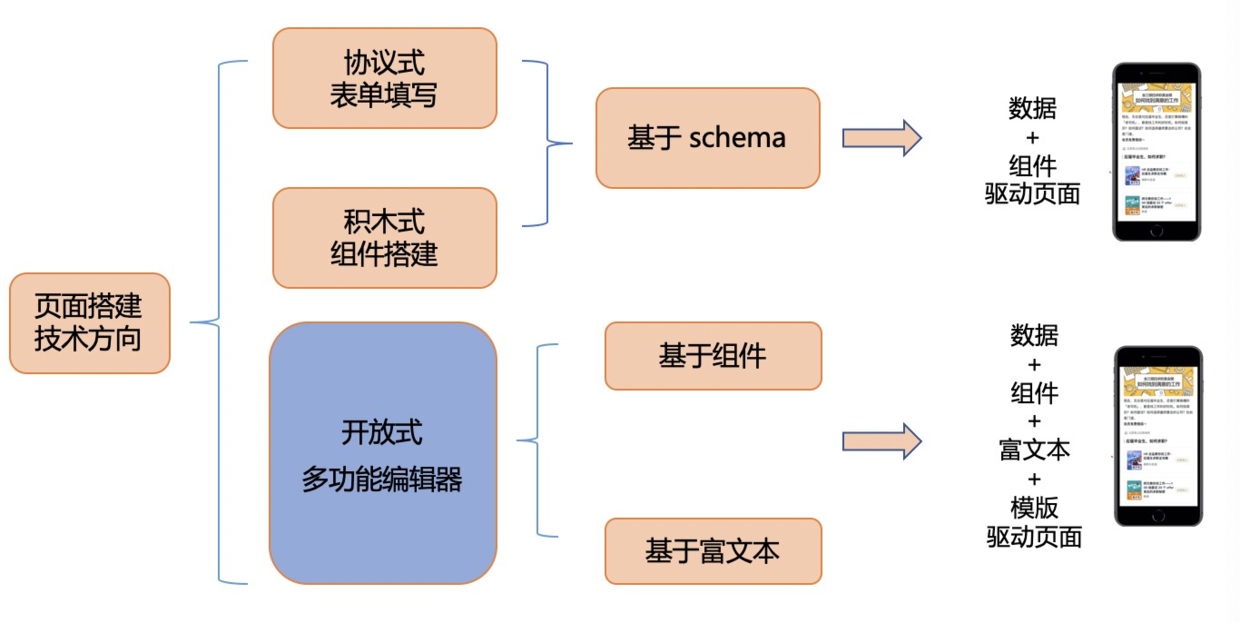
当编辑器技术遇见页面搭建需求
让我们先回到一个宽泛而有趣的问题上:“前端开发的难点到底在什么地方?”。
在这个问题下,旧有 @于江水 提到两个点:
- 业务逻辑很复杂而且多变
- 垂直领域解决方案并不简单
这里对其答案进行简单搬运和扩展,原答案可参考:于江水的回答。 顺着这个思路我们来分析,前面提到的运营活动页面——单纯开发这些页面难度其实不高。但是对于前端团队来说,如果高频多变的运营需求在短时间内集中爆发,那么就成了一个系统性的问题了。比如极端情况:对于淘宝双十一、京东大促,简单地堆人堆时间也只是杯水车薪。于是诞生了页面搭建平台。
这样一个平台涉及到的技术点是**网状的:比如涉及到开发工具链、数据结构设计、渲染器和交互设计、数据源导入、页面编译构建、页面生成、代码发布、活动发布、版本管理、在线运营管理、权限管理、可视化“所见即所得”实现、后端存储、CDN 同步、数据打点和统计、数据分析等。**后续结合平台化能力,也会涉及到组件市场的设计,甚至 serverless,no/low code 技术。
**而作为垂直领域一个不可忽视的方向——编辑器开发,技术难度只会更高:**除了编辑器本身的各种功能实现外,还需要兼顾兼容性,更要适应业务需求。同时,编辑器就是生产工具,任何一个中后台系统似乎都必不可少,需求市场上,不管是石墨文档、钉钉文档、头条飞书等都有着广泛而强烈的需求。该领域值得深耕而优秀开发专家却凤毛麟角。
为了解决「可视化搭建系统」,我们尝试把一个上述「复杂的业务平台」和「垂直领域的富文本开发」这两大难题结合起来,打造一个功能强大的编辑器,同时完成页面搭建平台的工作——这听上去虽然是“难上加难”,但似乎两大方向的融合是一种美妙的思路和创新。
具体来说,编辑器除了支持传统富文本功能以外,需要加入对业务功能区块的支持,这时候在数据结构上,选用 JSON base 的存储方式:传统富文本区块以 JSON 字段存储富文本内容,其它复合型自定义业务区块存储为 JSON 对象结构。在此基础上,我们实现对该 JSON 对象结构的解析,实现编辑器内“所见即所得”。
这里单独说一下富文本之外的“复合型自定义业务区块”。我们知道最终搭建出来的页面将会充满各种 Sku 商品、自定义组件、用户卡片等区块,最终这些内容的输出需要被 C 端渲染器所理解、所解析。
我们来结合下图,进一步说明:
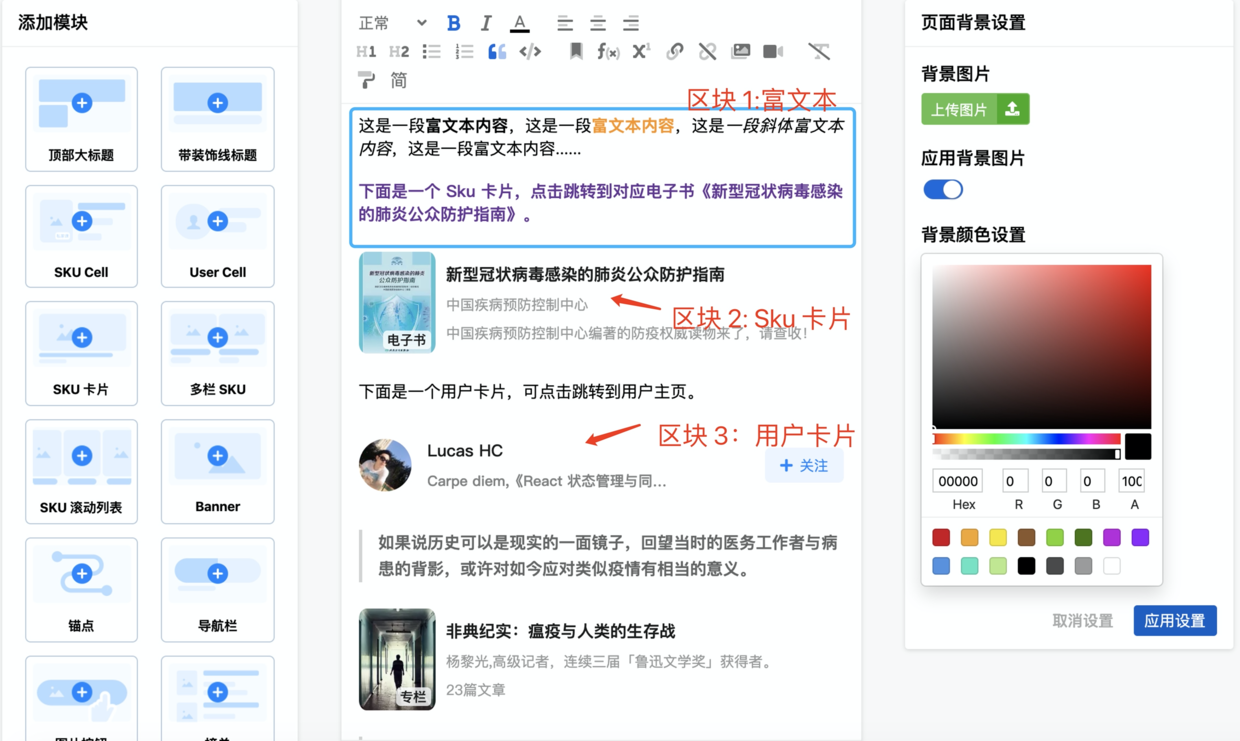
区块 1 是传统富文本内容,区块 2 是一个复合型自定义业务区块——Sku 卡片,区块 3 是另一个复合型自定义业务区块——用户卡片。这样一来编辑器不再是一个单一的富文本编辑器,而是最终输出内容为复杂 JSON 类型的多功能编辑器。
不同业务场景、特点,需要完全不同的前端解决方案,在开发这些垂直解决方案的时候,业务分析、技术选型、架构设计、开发落地是非常难的。接下来,就让我们一步步探索,一步步实现一个基于并兼顾编辑器技术的多功能的页面搭建平台。
灵活强大的 Markdown 编辑器和页面搭建创新尝试
我相信现如今没有程序员不知道 Markdown,它对程序员或者所有互联网从业人员来说都非常友好。简单说,Markdown 是一种轻量级标记语言,它允许我们使用易读易写的纯文本格式编写文档。现如今许多网站都广泛使用 Markdown 来撰写帮助文档或是用它来在社区上发表消息。比如:GitHub、Wikipedia、简书、reddit 等。
除了易于编写,Markdown 的可扩展性和可转换性也是它收到追捧的重要原因。也正因为如此,我们初期的运营活动页面搭建就是基于 Markdown 编辑器实施的。具体流程如图:
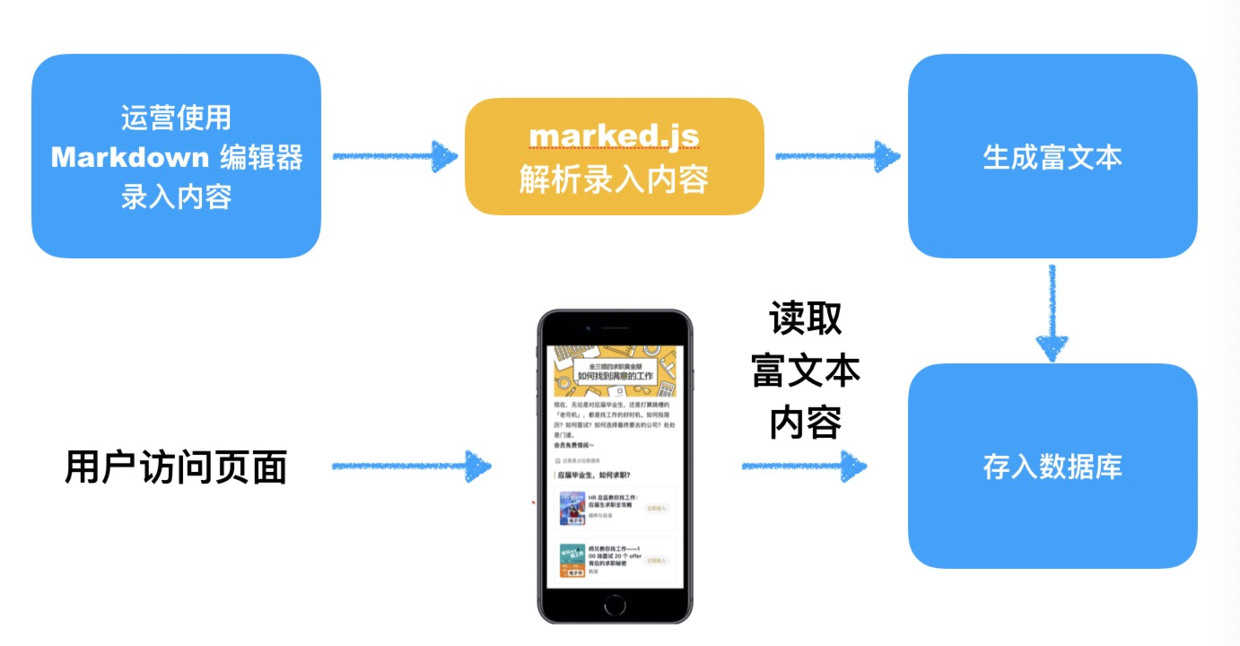
当然这只是一个非常粗略简易版的流程示意图,接下来我将分:
- Markdown 扩展和自定义解析器
- 完善使用体验,打造页面生成能力
两个方面进行详细解释。
Markdown 扩展和自定义解析器
Markdown 原本使用场景是面向文档和写作,它支持的标记和语法并不能满足所有场景需求。因此社区上存在不少 Markdown 解析器,其目的是对 Markdown 源内容进行解析和扩展。在众多解析器当中,最出名的就是 marked.js 了。这里简单对 marked.js 这个库原理进行分析,将会有助于理解后续我们的实现方案。
说起解析,其实就是经典的“编译原理”套路。套用在 marked.js 上,如下图:

工作机制很简单,marked.js 接受输入源文本字符串后,创建词法解析器实例:
const lexer = new marked.Lexer()
词法解析器实例 lexer 的使命是将输入源进行分词,解析出 tokens:
const tokens = lexer.lex(content)
如何理解分词生成的 tokens 呢?其实 tokens 就是 AST 对象(或直接把它理解成 json 数据,它是树形结构,表达出 Markdown 中段落,块引用,列表,标题,规则和代码块等信息)。
接下来,marked.js 实例化一个解析器:
const parser = new marked.Parser()
该解析器 parser 接收 tokens,根据 tokens 生成 html 富文本:
const html = parser.parse(tokens)
当然,这只是很粗略的流程,但细心的读者可以窥出端倪:**如果想扩展 Markdown 语法:我们可以修改 lexer 生成 tokens 的函数,目的是加入我们的自定义 Markdown 语法解析成新类型 token 的能力;同时修改 parser 解析函数,根据新 token 类型,生成我们预期结果。**这里我不在深入赘述这个过程,事实上,我们采用的方案也没有 fork 去修改 marked.js 代码,而是自己基于 marked.js,封装了更上层的解析器。
完善使用体验 打造页面生成能力
由上可知,我们的页面搭建需求主要集中在插入各种组件卡片,插入带链接 banner 图片等复合型自定义业务区块。这每一个需求都应该对应一个 Markdown 的新语法规则。
比如,输入:
<SkuCell>live@12345@rondStyle</SkuCell>
则表示页面中插入一个 id 为 12345 的 Sku 卡片。
如果让运营同学手动输入上述语法内容无疑是痛苦且不可接受的。因此我们设计了 Markdown 编辑器的按钮:「添加 Sku Cell」,点击按钮之后,会弹出表单对话框,由运营输入 Sku 类型和 id ,即可自动在 Markdown 编辑器中光标所在位置插入一行内容:
<SkuCell>live@12345@rondStyle</SkuCell>
这样的设计方便运营使用和记忆。因此对于使用者来说,只需要了解基本的 Markdown 语法,而不需要再去记牢和手动输入新型语法。
**为了满足“所见即所得”需求,我们需要在运营键入内容时,同时进行对输入源的解析。**解析的过程需要逐行进行:
- 如果解析当前行内容符合 Markdown 原始语法,则用 marked.js 进行解析,得到解析出来的富文本结果,推入结果数据栈(这里的数据栈是一个 result 数组)
- 如果解析当前行内容符合新扩展的 Markdown 语法,则使用自己的解析器函数(暂且命名为 feParse)对该行进行解析(解析器函数实现是一个简易的编译分词过程)
- feParse 函数接收扩展新语法内容,对于不同表意方式使用不同的 helper 处理,比如处理
<SkuCell>live@12345@rondStyle</SkuCell>将会被 skuCellHelper 函数处理 - skuCellHelper 函数解析内容,分析得到分词结果(标记为 formData):
type: 'live',
sku_id: 12345,
style: 'rondStyle'
- 根据上面分词结果,请求后端接口,获取该 Sku 对应的数据,比如该 id 为 12345 的 live 数据(标记为 liveData):
author: 'live 作者名',
id: 12345,
created_date: '2019 10-12 20:34',
description: 'live 介绍',
duration: '20mins',
// ...
- 根据以上两种数据:formData 和 liveData,利用 React 服务端渲染能力,获得该 Sku 组件对应的富文本 skuRichText:
const skuRichText = ReactDOMServer.renderToString(<SkuCell data={... formData, ... liveData} />)
- 将 skuRichText 推入结果数据栈 result
最终我们逐行解析的结果产出为:
result = [
'第一行富文本内容',
'第二行 Sku 卡片对应的富文本内容',
// ...
]
合并 result 内容,渲染出富文本,显示在页面右侧,实现所见即所得效果。
总结一下实现“所见即所得效果”的要点为:
- 自定义 Markdown 语法解析器
- 利用 React 服务端渲染能力得到特殊组件的富文本内容
需要指出的是,在实际实施当中:运营在编辑器中,保存并提交给后端的数据区别于上述 result,它也是一个数组:submitData,用来表示运营输入的内容。对于原始 Markdown 语法,我们直接使用其对应的富文本内容;对于新的扩充语法,我们并没有使用其对应的富文本内容,而是使用了上述 formData 的数据结构,最终提交类似内容:
submitData = [
{
type: 'richText',
content: '<p>XXXX</p>'
},
{
type: 'sku',
content: {
type: 'live',
sku_id: 12345,
style: 'rondStyle'
}
},
// ...
]
**这样的考虑是为了 C 端用户在请求页面时,能够获得最新的实时 Sku 数据。**如何理解实时 Sku 数据呢?在运营编辑页面时,假设插入一条 Sku 的标题信息为“标题一”。再一天后,该 Sku 的标题信息变成了“标题二”。如果我们保存并使用了运营编辑时使用的富文本信息,那么 C 端页面一定是“标题一”,而不是最新的“标题二”。因此我们只提交该 Sku 的 id。当有 C 端用户请求页面时,由后端通过 RPC/Http 调用,获取最新的数据,并由组件在服务端渲染出内容,最终返回给前端。
整个流程如下:
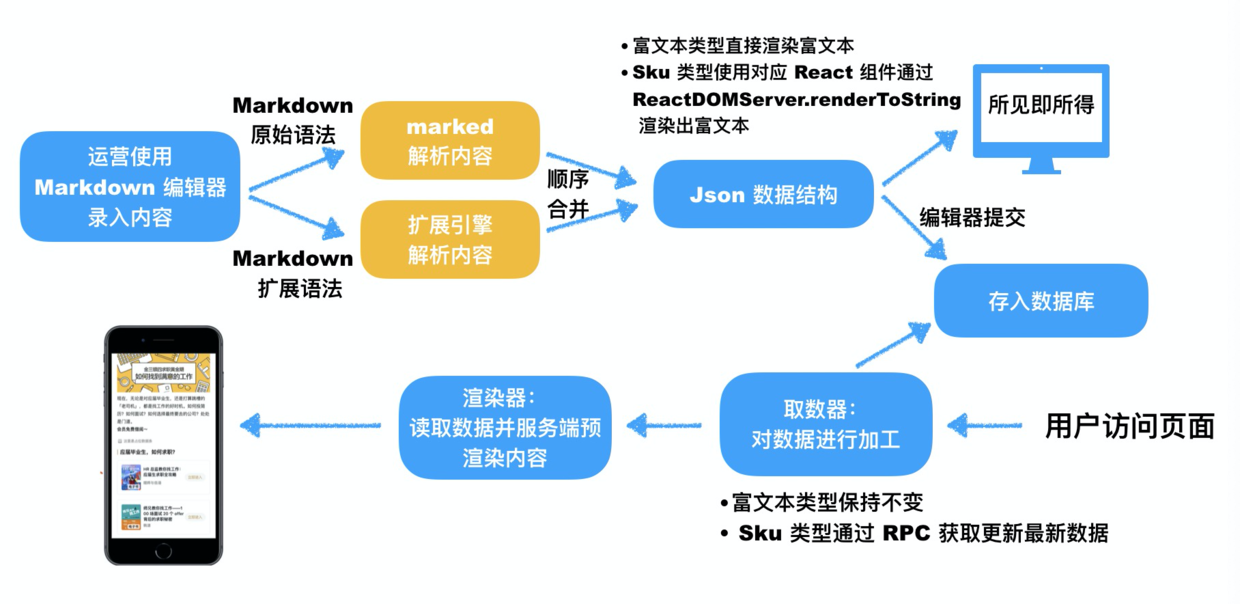
到此为止,我们实现了一款基于 Markdown,利用 Markdown 语法灵活性,扩展而成的编辑器。这个编辑器中内置了诸如「插入 Sku 卡片」、「插入 Banner 图」等一系列的业务功能。
基于这套思想,我们完成了帮助运营快速搭建活动页面的复合型编辑器和页面生成器,它的优点非常明显:
- 输入即所见,所见即所得
- 支持灵活扩展,可以基于解析器支持所有类型的语法和任意组件
- 运营只需要熟悉基本的 Markdown 语法即可,扩展语法由点按按钮完成
最终效果图:
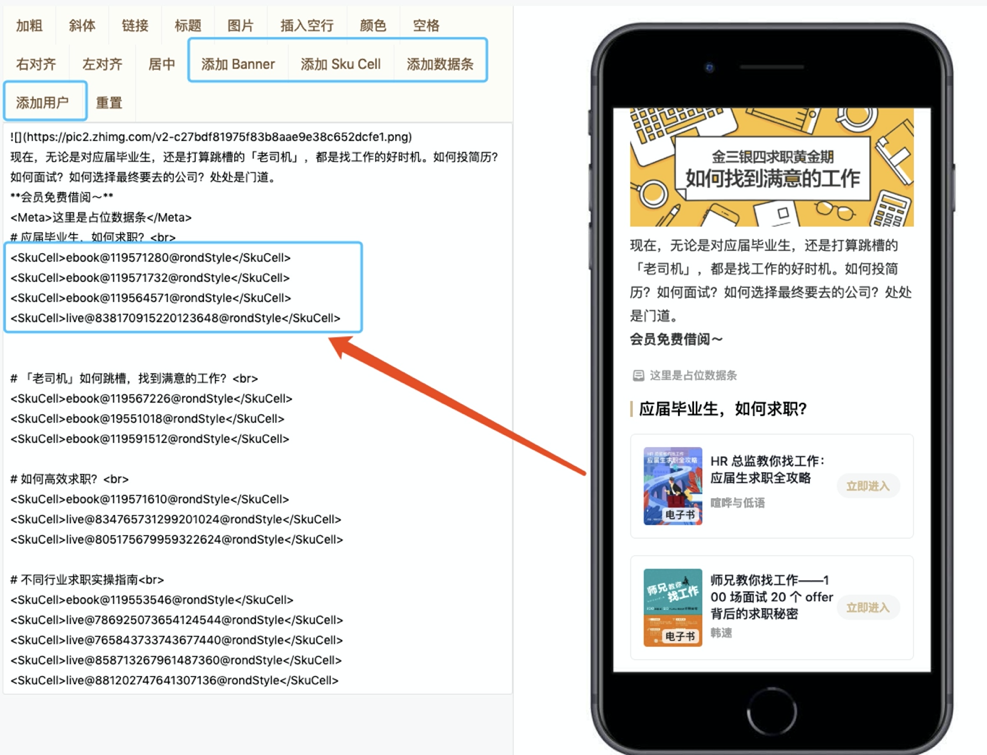
**技术方案都是在不断演化推进当中发展并完善的。在该平台运行半年多之后,我们大胆进行了创新优化,并最终用更高效的方案实现了全面替换。**感兴趣的读者请继续阅读。
不止是富文本编辑器
上面我们提到了已有复合型编辑器即页面生成器的优点,经过半年多的线上服务后,我们再去深入分析一下它的缺点:
- 编辑器内 Markdown 语法内容,对于运营仍然较为晦涩难懂
- 运营还是需要一定的学习和使用成本
- 依赖实时解析和渲染的“所见即所得”
- 对于每一种新的组件,都要创建一种新的 Markdown 语法
这些缺点很好理解,这里着重讲一下“所见即所得”。**上面我们提到“所见即所得”,实际依赖了实时解析内容源为全量富文本,并实时渲染富文本的能力。**虽然满足了需求,但是这样的做法性能成本较高,即便加上常用的“防抖和截流”手段,对于浏览器的压力仍然不小。能不能像“积木系统”、“拖拽搭建页面系统”一样,直接在“画布”上修改,做到更加真实的“所见即所得”呢?
“拖拽系统”优缺点鲜明。 首先,以大量 H5 生成工具为代表的拖拽系统虽然看上去功能强大,但是本质上却是依靠组件的堆积和无穷尽的配置扩展,最终产出的数据形态和功能野蛮生长下去,比较容易出现“失控”的局面,而逐渐被边缘化。 这里的失控既指运营侧、产品设计侧没有统一约束,也包含了代码膨胀后的维护角度的失控。另一方面,从最终结果上看,拖拽系统将页面的拼接转嫁到运营身上,这些“搬砖”的工作量对于运营其实也并不算小,同时它缺少“规范化”的强制约束,不利于视觉设计的统一,运营同学“自我发挥”反倒不一定完全是好事。退一步来说,社区上已经存在不少可用的拖拽系统,重复造轮子也毫无意义。
结合我们的需求特点:页面区块和设计样式固定、组件形态固定、页面排版固定、重文字和图片内容、页面交互并不复杂,我们认为,多功能富文本编辑器将会是一个值得深入试水的方向。
传统的富文本编辑器就是一个强大的“超级文字加工厂”,类似我们常用的 word,运营可以在其上“肆意挥洒”。如何在富文本编辑器上,加入设计规范,并实现业务组件添加呢?
首先,富文本编辑器是前端一个非常值得深入研究的重要方向,社区上各类开源富文本编辑器也不在少数,但是从时间和开发成本的角度来看,我们既不想重新实现一个融入了自己业务的增强型富文本编辑器;又不想做各种魔改已有方案。
无法找到一个合适的解决方案,还是让我们先从需求角度分析:
- 新型多功能富文本编辑器,需要支持历史上的 Markdown 语法数据,否则会出现历史数据不兼容的线上问题
- 新型多功能富文本编辑器,不仅为页面生成器服务,也要能够支持多类型横向业务以及纯富文本编辑器业务
- 新型多功能富文本编辑器,要支持所有富文本的特性,包括复制粘贴内容等
- 新型多功能富文本编辑器,要支持插入自定义组件和区块,比如 Sku 卡片等
- 新型多功能富文本编辑器,应该插件化,可插拔
- 新型多功能富文本编辑器,要做到完全的所见即所得
- 新型多功能富文本编辑器,要支持模版形式快速搭建页面
- 新型多功能富文本编辑器,要接入格式自动规范机制,自动实现标点挤压、统一排版等功能
综上需求和设计方案,我们选用了 Draft.js 作为这套多功能编辑器的底层框架,一句话足以总结做出该选择的原因:**Draft.js 实际上并不是一个富文本编辑器,它其实是一个用于构建富文本内容和富文本编辑器的基础设施。**做个比喻:如果把富文本内容比作一幅画,Draft.js 只提供了画纸和画笔,至于怎么画,开发者享有很大的自由 ——(出自文章:Draft.js 在知乎的实践)。
这正符合我们的需要:我们不要一个完整的解决方案,而需要一个舞台。至于如何解析内容,如何渲染内容,如何生成数据,应该全部由开发者把控。事实证明,这样的创新设计对于页面搭建生成器以及传统编辑业务场景非常贴合,我们最终实现了目前服务于后台系统的强大多功能编辑器 —— Versatile Editor。
Versatile 译为“多才多艺的;有多种技能的;多面手的;多用途的,多功能的”。目前 Versatile Editor 已经全面接管了所有后台系统编辑需求。它的技术设计和体系也非常清晰。下面我们主要从
- 数据结构设计
- 插件体系设计
- 多数据源支持
- 使用体验设计
- 页面模版支持
- 其他细节
六个方面进行分析。
别具匠心的数据结构
**数据结构的设计思想是:**使用结果数据栈(数组)存储每一个 Draft.js 编辑器块级内容,数据每一项都顺序对应每一个块元素。这些块元素分为两大类:纯富文本内容和纯自定义组件内容。对于纯富文本内容,我们重新实现了将 Draft.js 的不可变数据结构解析转换为富文本的工具函数 draftToHtml;对于纯自定义组件,我们只提取出组件最小还原数据(比如 Sku Cell 组件的 sku id 等信息)。
运营在编辑器侧提交流程如下图:
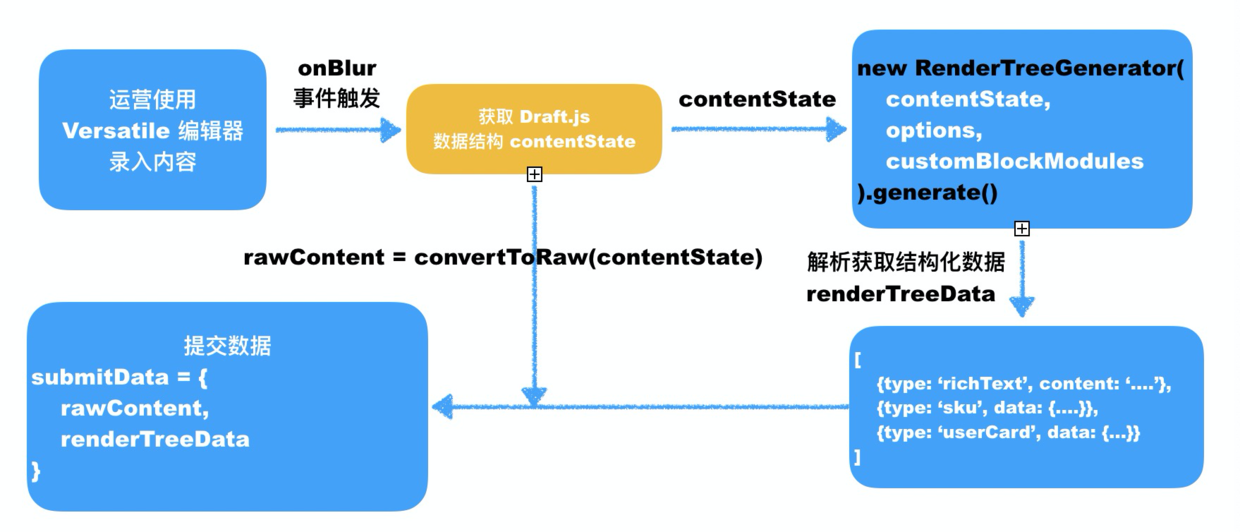
具体说明一下图中的核心 contentState。contentState 是 ContentState 类型的对象,它规定了如何存储具体的富文本内容,包括文字、块级元素、行内样式、元数据等。
这里需要注意的一点是:在输出数据上,我们至少提交两种数据给后端存储:
- rawContent
- renderTreeData
其中 rawContent 是根据不可变数据 contentState 进行序列化后的结果,rawContent 可以通过数据表示出当前编辑器内所有内容。我们提交 rawContent 的目的是用于编辑还原。当运营再次打开编辑器时,编辑器可以根据 rawContent 迅速渲染出上一次提交的所有内容,以供编辑。
**而 renderTreeData 是经过计算并处理后提交的数据,它的目的是存储到数据库中,用于后端返回给 C 端页面,C 端页面最终根据 renderTreeData 由渲染器渲染出完整的活动运营页面。**由上图可知,renderTreeData 的生成,我们开发了 RenderTreeGenerator 的实例上 generate 方法:
new RenderTreeGenerator(
contentState,
getToHtmlOptions(contentState, this.props.editorConfig),
this.customBlockModules
).generate()
如图:
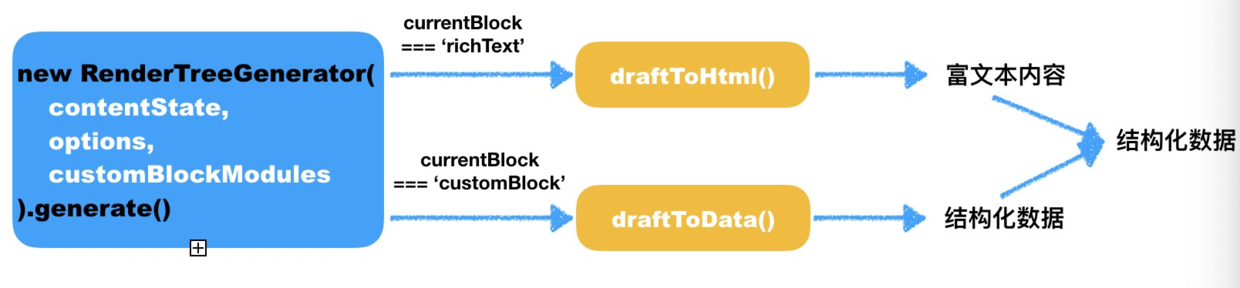

RenderTreeGenerator 接受 Draft.js 的不可变数据类型 contentState 作为第一个参数,自定义配置项作为第二个参数,React 组件集合 this.customBlockModules 作为第三个参数。this.customBlockModules 是一个数组,包含了所有自定义区块 React 组件名,在自定义区块类型命中该数组时,需要启动自定义区块,并生成结构化数据。
generate 方法简单伪代码说明如下:
generate() {
this.output = []
this.blocks = this.contentState.getBlocksAsArray()
this.totalBlocks = this.blocks.length
this.currentBlock = 0
this.indentLevel = 0
this.wrapperTag = null
this.richTextArray = []
this.finalOutput = []
const processRichText = () => {
this.output.push({
type: 'RICHTEXT',
data: this.processRichText()
})
}
while (this.currentBlock < this.totalBlocks) {
const block = this.blocks[this.currentBlock]
let blockType = block.getType()
let type = blockType
// 对于 atomic 类型,如果当前类型在 this.customBlockModules 当中,则 export 出渲染数据以及当前 type
if (block.getEntityAt(0)) {
const entity = this.contentState.getEntity(block.getEntityAt(0))
type = entity.getType()
if (this.customBlockModules.has(type)) {
const entityData = entity.getData()
this.output.push({
type,
data: entityData
})
this.currentBlock += 1
} else {
// 不在 this.customBlockModules 当中,仍按照富文本导出
processRichText()
}
} else {
processRichText()
}
}
// 其他美化或清理工作,比如连续富文本区块的合并
return this.finalOutput
}
这里不同于前期 Markdown 编辑器的关键点主要有两处:
- 我们监听编辑器区块的 onBlur 事件,在此事件触发时,开始生成结果数据
- “所见即所得”——不再需要在手动实时解析渲染实现。因为 Draft.js 是一个基于 React 的编辑器,我们可以直接在编辑器中渲染出一个 React 组件
如下图:
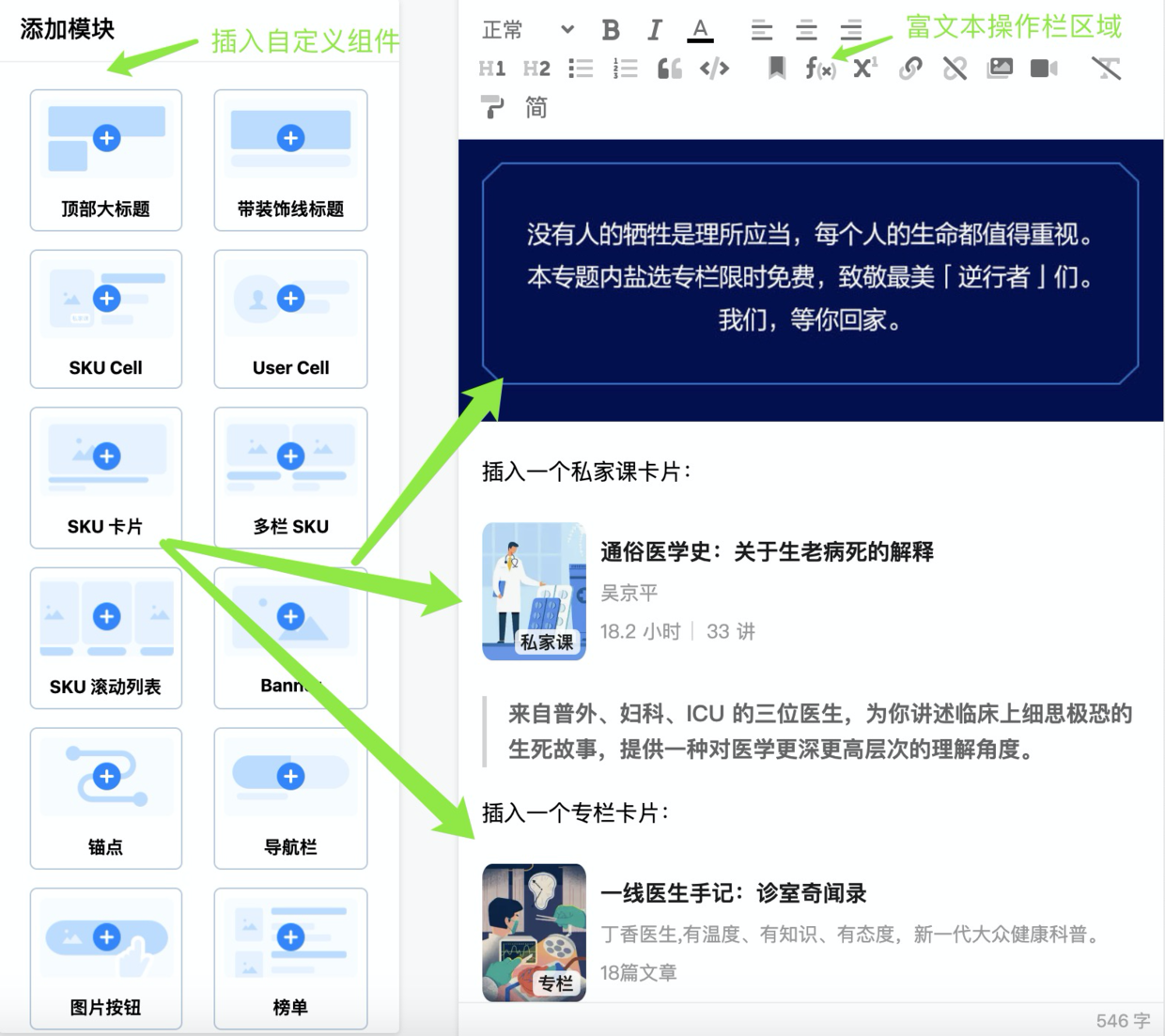
以上两个特征也正是基于 Draft.js 的多功能编辑器优于 Markdown 编辑器的关键点。
可插拔、可移植的插件化和组件化设计
多功能编辑器的多功能不是说说而已,为了支持海量功能需求,且考虑到方便第三方功能扩展,我们设计了良好的编辑器插件体系。**目前项目中使用了 11 个插件,它们涵盖了:**插入代码、插入公式、插入链接、插入引用、插入视频、复制粘贴还原内容、插入图片、插入重点样式、插入注解等。**项目还沉淀出来海量业务组件,包括:**页面喵点组件、Banner 图组件、Sku 卡片组件、各类按钮组件、滚动列表组件、图片画廊组件等。所有的组件和插件原则上都是可以面向社区、面向第三方使用的,同时后续计划只需要一个 NPM 包即可接入一个新的功能或新的自定义组件类型。**这也为后续的组件市场设计、no/low code 设计打下了基础。
在编辑器初始化时,我们注册并实例化各种插件以及自定义组件。因为我们多功能编辑器的理念就包括了结构化和数据化,所有的这些插件和组件都可以依赖 decorator 进行解析,这也就意味着:从另外一处编辑器实例中复制任何内容(包括自定义组件)到当前编辑器,都可以直接还原数据,无缝完美支持组件的复制粘贴功能。
多数据源支持
任何一项技术创新和更迭,都要考虑历史包袱和历史债务的解决。多功能编辑器也不例外,前面提到,历史编辑内容是使用 Markdown 格式的。以运营页面生成器场景为例,历史活动页面 A 对应的后端存储数据是 Markdown 字符串。我们在使用新的多功能编辑器替换旧的 Markdown 编辑器后,如果运营同学想再次编辑活动页面 A,新的多功能编辑器上自然就要兼容历史内容。
**为此我们的方案是:**在编辑器中接收到数据源后,如果嗅探为历史 Markdown 格式,那么先利用 marked.js 将此 Markdown 格式内容转换为富文本内容,再根据富文本内容转换为 Draft.js 支持的不可变数据结构。
总结一下,对于编辑器初始化时的数据源(rawContent)处理流程如下图:
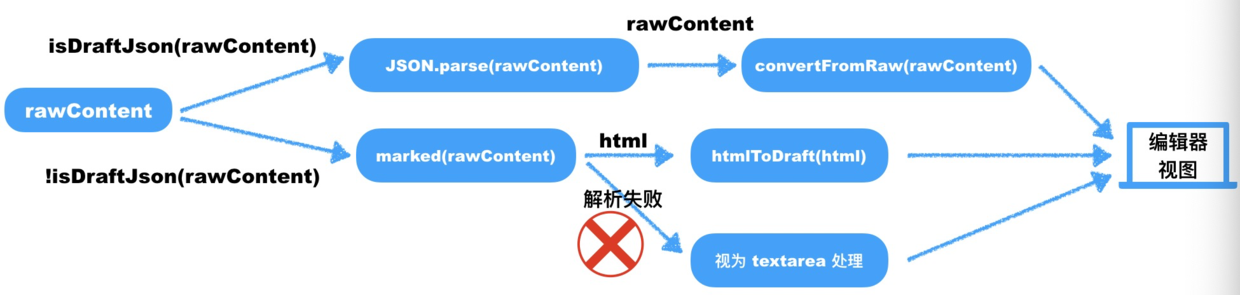
对于编辑器获取的数据 rawContent,我们使用 isDraftJson 工具函数判断该 rawContent 是否可以被多功能编辑器以 Draft.js 支持的数据解析:如果可以,则证明 rawContent 为由新的多功能编辑器提交的数据,可以直接使用并恢复出编辑器内容。如果 isDraftJson(rawContent) 判别为 false,那么就表示无法被 Draft.js 解析,需要兼容历史 Markdown 语法,由 marked.js 解析出富文本后再交给 Draft.js 处理,由富文本生成 Draft.js 的不可变数据;如果解析都失败,则直接将 rawContent 视为 textarea 内容,直接填入到编辑器当中。
图中并未画出如果 rawContent 为空(或不存在)时的处理方式。实际上,如果 rawContent 为空,我们使用 ContentState.createFromText('') 方法生成一个初始化为空内容的不可变数据。
实际过程由于历史包袱原因,对于多数据源的支持实现更为复杂,这过于特殊,我们不再展开。
持续打磨使用体验
编辑器一个非常重要的话题就是体验。相信很多人都经历过编辑器的体验之殇:“输入卡顿、诡异的光标位置”等,但这里我认为没有必要分析传统编辑器的体验优化话题,更有意义的是从我们特有的多功能编辑器特点入手,聊一聊用户体验。
举一个例子:按照 Draft.js 的设计,每一个区块之间上下都会有个空行。如图:

这样会导致提交编辑器内容时,生成的自定义区块数据前后会包含了两个空区块数据,最终导致渲染出的页面也会包含两个空白行,直接影响页面设计效果。社区上关于这个设计的 issue 讨论不少,比如 Empty line on adding atomic block。
**事实上,这是为了灵活地在自定义区块前后添加或删除内容。**设想,如果我们连续添加了三个自定义区块——Sku 卡片 A,Sku 卡片 B,Sku 卡片 C。**如果 A,B,C 之间没有空行,那么我们如何在卡片 A 和卡片 B 之间插入一个新的卡片 D 呢?**如果 ABC 卡片彼此之间保持一个空行,那么使用者可以用光标定位到 AB 之间的空行,再插入卡片 D。这就是自定义区块前后自动存在空行的意义。
有的开发者可能会想:我们可以保持这个空行的存在,在最终生成的数据时,自动将空行删除不就可以了吗?事实上,拿到 Draft.js 编辑器的数据时,我们无法判断是用户自主回车创建的预期中的空行,还是自定义区块自带的前后空行,因此无法直接在结果数据上粗暴地移除空行。
为了达到更好的使用体验:我们开发的 FocusPlugin 插件,优雅地解决了问题:依然是每一个自定义区块前后不保留空行,但是利用 FocusPlugin 插件,使得每一个自定义区块都可以被点击选中,或者用键盘上下键遍历选中,选中之后可以直接摁下回车键,添加空行,甚至可以摁下 delete 键,删除该区块。如图:当自定义区块被选中时:
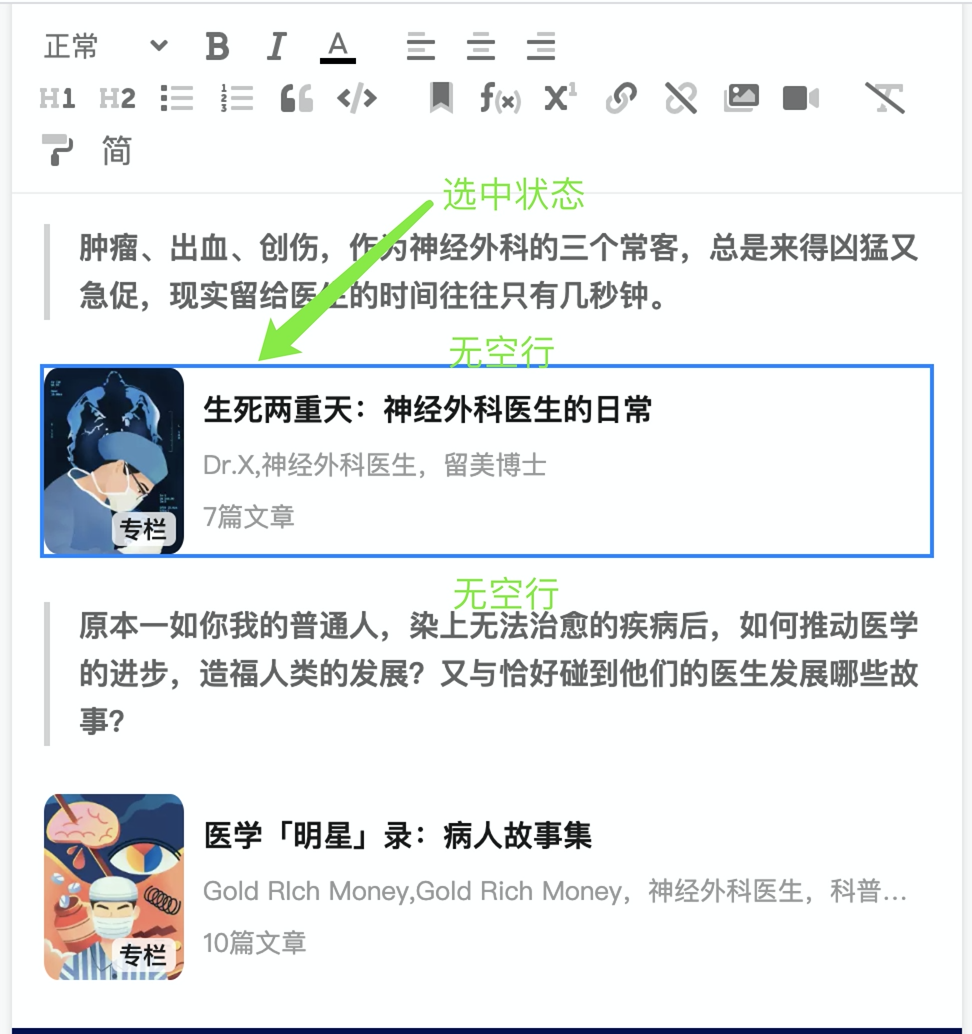
最终这套基于 FocusPlugin 插件的方案使得交互更加顺畅自然,达到了更好的效果。基于此,我们可以非常顺利地完成自定义区块的更改:比如当前选中区块为一个 id 是 1234 的 Sku 卡片,如果运营需要替换为 id 是 5678 的 Sku 卡片,只需要选择当前区块,选中之后在右侧出现的编辑区中更改 id 内容,确定后即完成替换,如图所示:
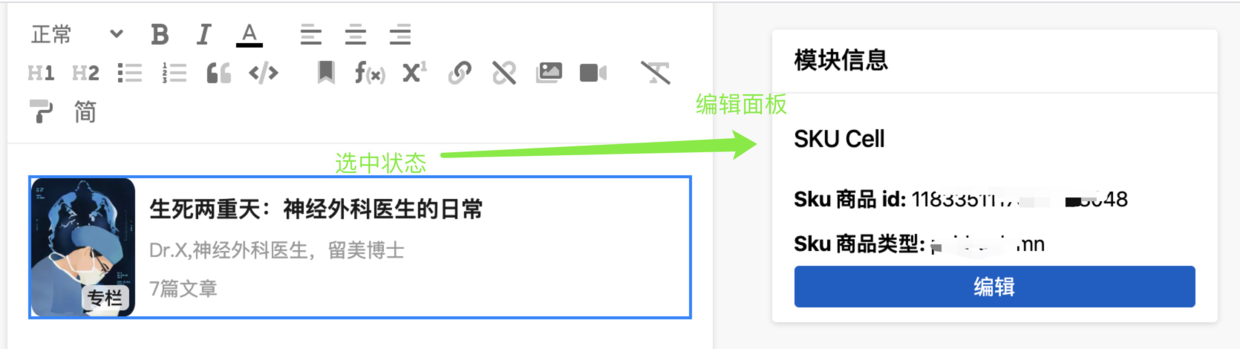
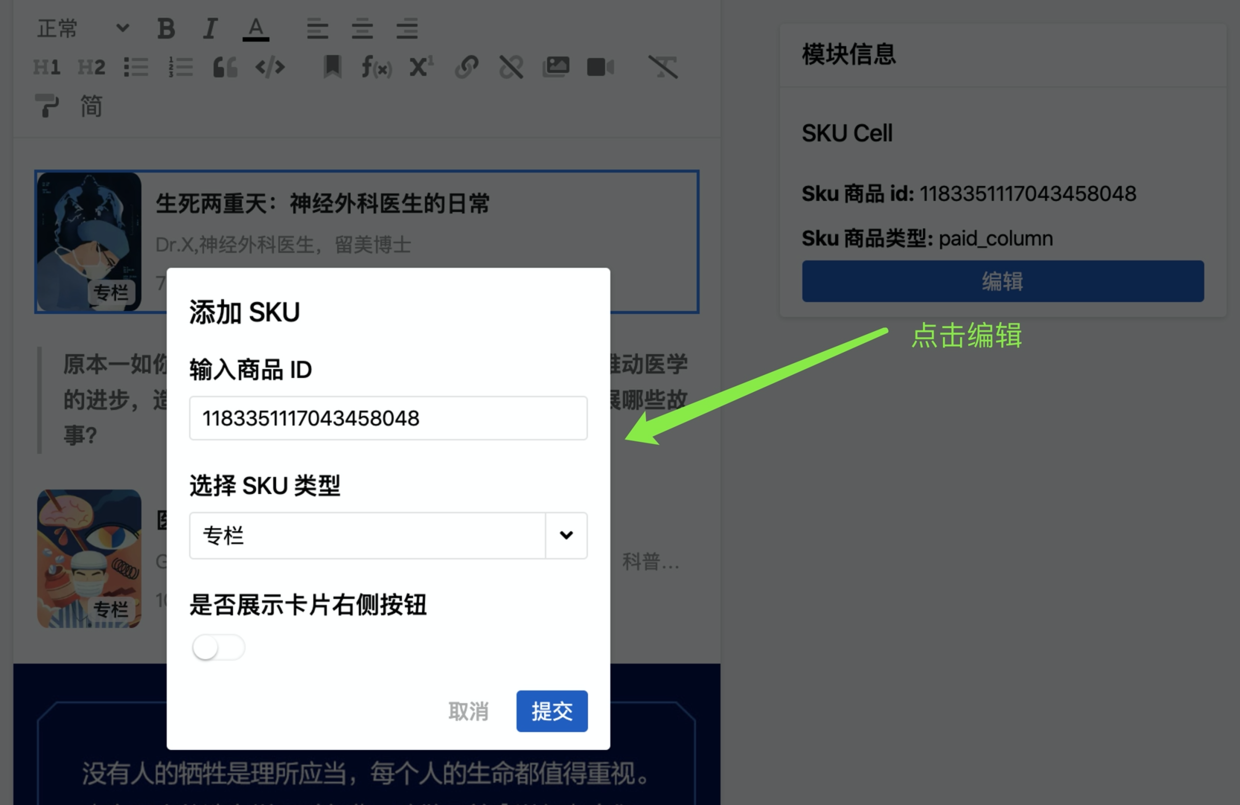
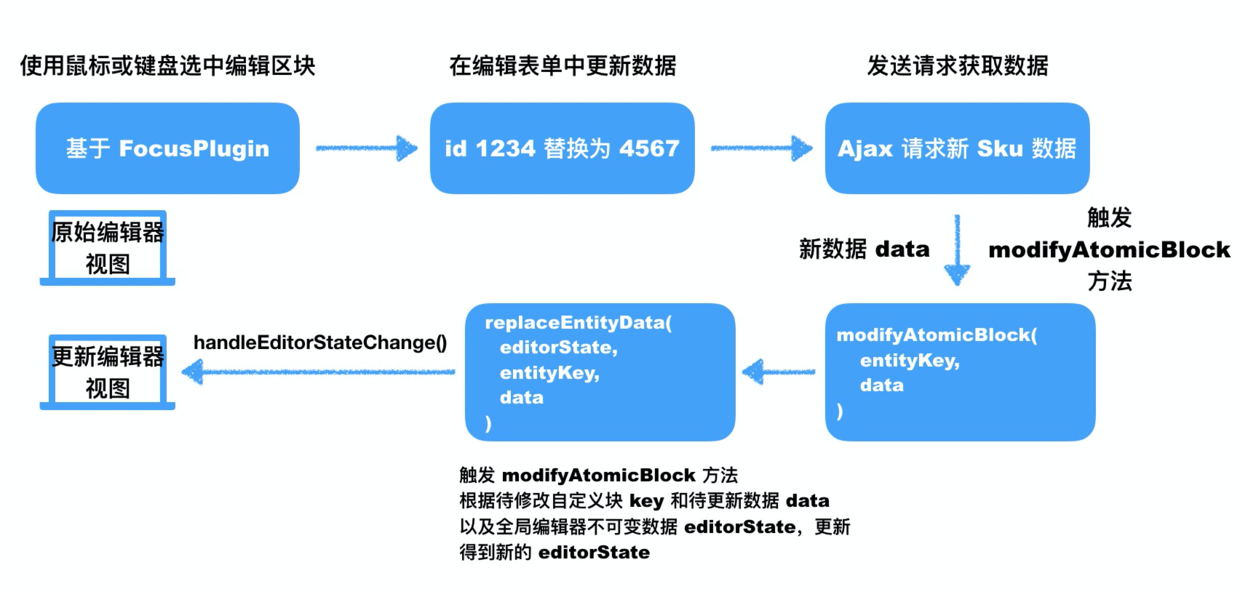
基于 FocusPlugin 插件,以修改当前 Sku 卡片 id 为例,id 进行修改后,发送获取新的 id 的数据,并在数据成功获取后调用 modifyAtomicBlock(entityKey, data) 方法,触发 replaceEntityData(editorState, entityKey, data) 方法进行编辑器不可变数据的更新,并由 handleEditorStateChange 方法一并更新状态,最终反应在编辑器视图中。
这一编辑发生过程总结图为:
使用体验确实不是一蹴而就的的事情,这是一个需要持续迭代优化的过程。经过不断地打磨,Versatile Editor 最终趋于稳定。目前 Versatile Editor 已经支持了数百量级的页面搭建,以知乎投放的页面为例,包括但不限于:
页面模版支持
Daft.js 编辑器内容是完全基于数据状态的,它使用了不可变数据库进行数据的更新操作,秉承纯函数式更新,因而天然对于“时光旅行(Undo/Redo)”的特性能够良好支持。另一方面,一切皆数据也让我们实现“页面模版”功能非常简单而巧妙。
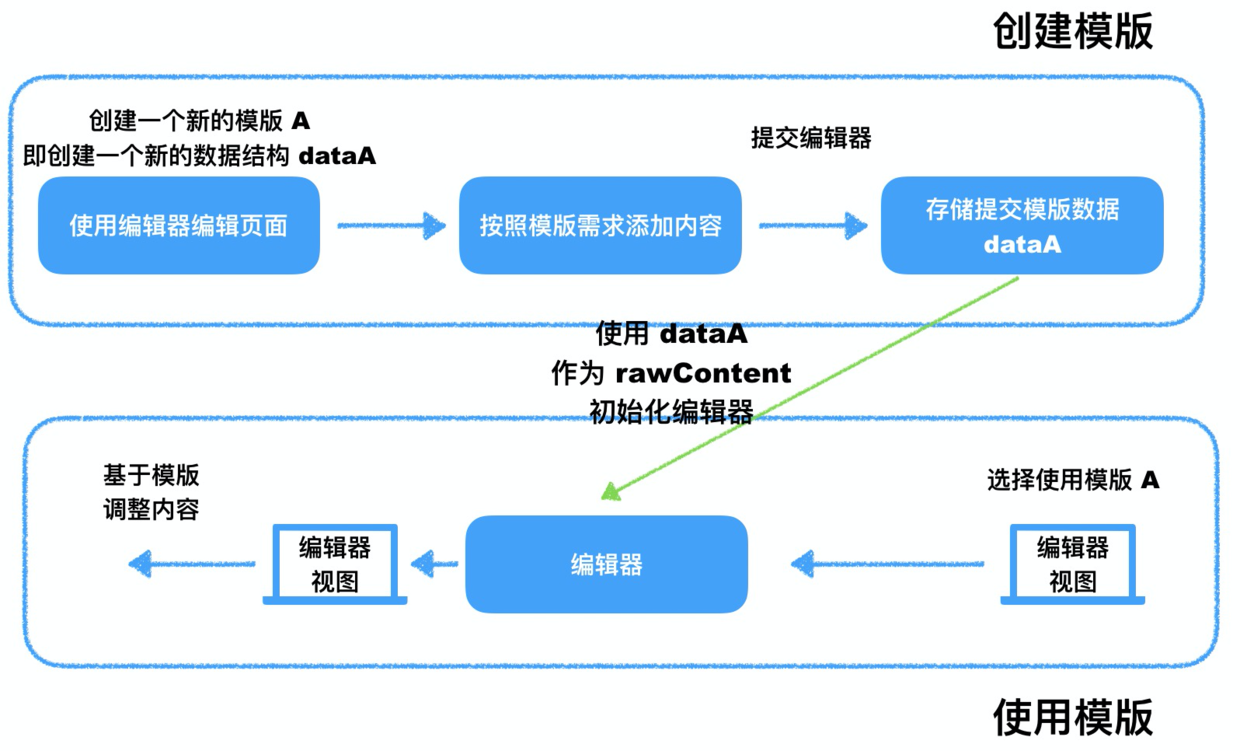
我们可以将所有模版拆分为几个大的自定义区块,并创建这个活动模版所对应的数据:比如对于模版 A:头部为一个头图 Banner,我们可以编辑器中创建一个由占位图表示的 Banner 图片;第二区块为电子书榜单 Top10,即可在编辑器中创建一个 Ranking 组件,并由任意占位 10 个电子书数据填充,以此类推。提交数据之后,即可获得描述这个页面模版的数据。
当运营在创建页面,并选择使用「排行榜模版 A」时,我们就用已经提前预制的数据作为 rawContent 进行编辑器初始化。得到模版后,运营即可添加修改,快速完成模版页面创建。
整体流程如下:
其他细节
到此为止,我们介绍了社区方案和我们自己持续迭代的方案。其中还有一些小的细节在这里简要带过,主要包括:预览、排版、安全性、配置系统几个方面说明。
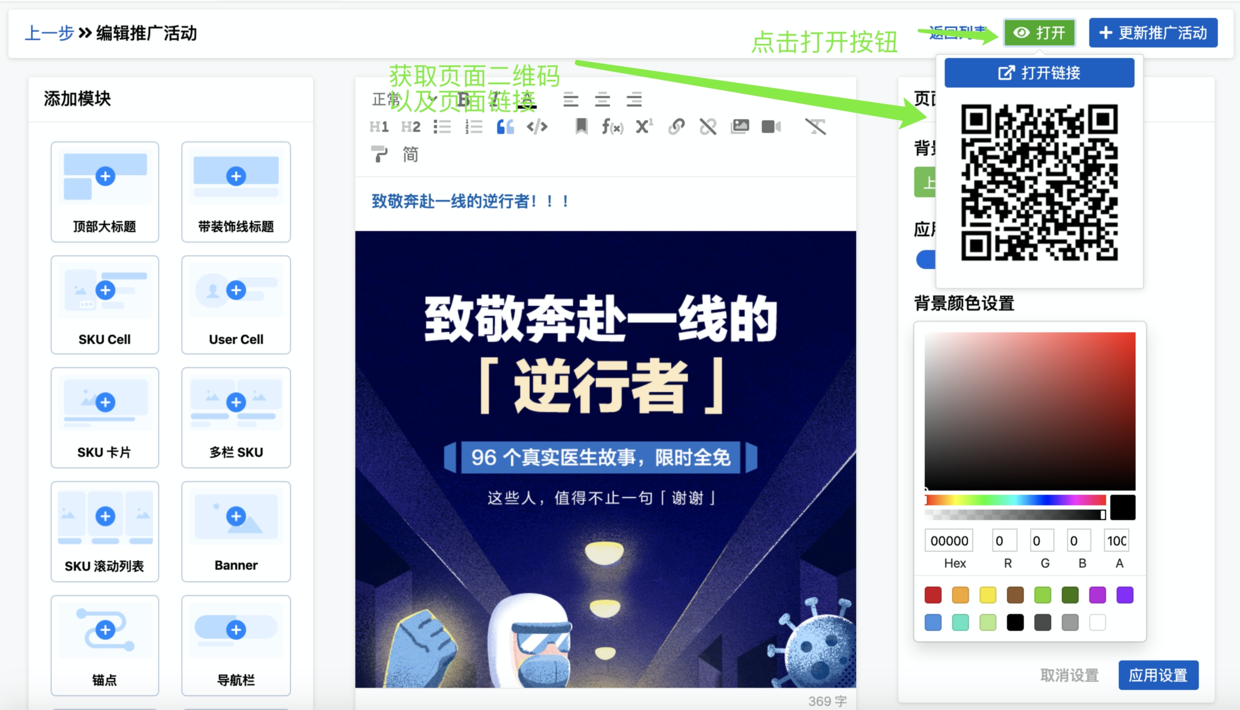
“所见即所得”使得运营编辑活动效率大幅提高,但是在编辑器提交发布和推广之前,还是需要一个完整的可预览页面地址供进一步回归。由于这些推广页面都是面向移动端,因此我们在这个多功能编辑器兼页面生成器的产品设计上,预留有页面发布地址和二维码生成功能,进一步优化运营使用体验。如图:
另一方面,我们对于页面文字的编审有着严格的要求,比如:不能使用中文引号,需要使用「」;英文和数字与其他汉字之间需要预留一个空格;甚至标点的位置也有严格规范,需要实现传统类似“标点悬挂、标点挤眼”等一系列排版需求。因此,该多功能编辑器兼页面生成器配置了可插拔的自动排版能力,主要完成自动排版规范的审校和修正,如图:
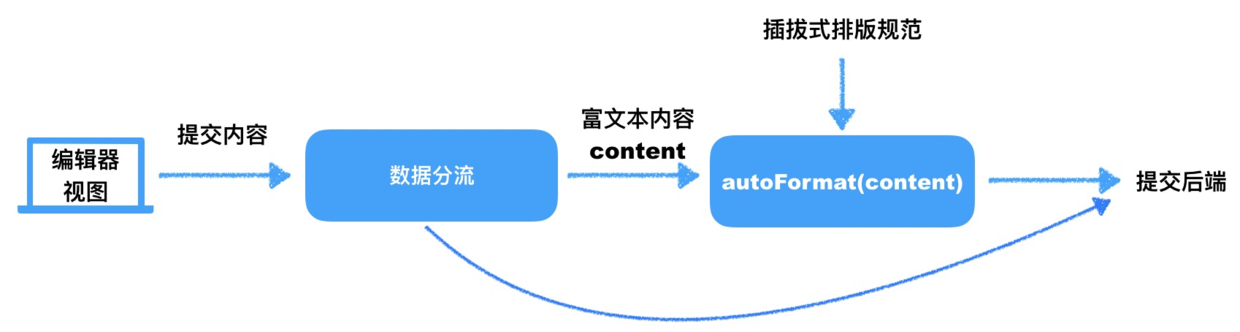
一个页面往往无法只由编辑器生成,可能还包括配置内容。这些配置需求我们用进入编辑器之前的表单来承载,表单填写完毕,生成基础配置数据后,再进入编辑器进行创作。表单是页面中数据交互的基本形式,对于非开发人员使用也没有使用门槛,但是切记不可将表单设计的过于复杂。同时要注意,编辑系统和配置系统需要解偶的原则。
**前面提到编辑器就是生产工具,编辑器的效能就意味着生成效率。一旦编辑器出现线上问题,那么就会直接影响正常的生产活动。**因此,为了保障编辑器的安全性和强健性,我们加入了测试环节。主要包括:单元测试,UI 测试。单元测试主要验证关键函数和方法的正确性,比如上面提到的 autoFormat 方法,各种插件的输入和输出正确性校验,数据修改的工具方法校验等;UI 测试主要依靠 Enzyme,来保证关键交互的正常运行。
最后,其他涉及点比如:一键换肤、字数统计等由于篇幅原因,这里都不在详述。
富文本编辑器是一个深坑,Draft.js 虽然背靠 Facebook 团队,但也一直在深坑中挣扎,我们此间开发过程确实是一部血泪史,但我们团队也在此方向积累了丰富的经验,后续技术细节也会一一进行分享,请持续关注订阅。
总结
**我一直在思考,什么样的文章能够给读者带来真正的思考和启迪。**一方面入木三分讲解语言特性和设计,深入技术细节,庖丁解牛般的分析是我们所需要的,这类文章需要靠代码说话;另一方面,总结梳理技术趋势,从更高的角度叙述方案的落地和演进,更是对大局观和格局的培养,这对于团队的技术规划和舵向同样至关重要。
这篇文章粗浅总结了业界在「可视化页面搭建」技术探索的方方面面,并整理了各种相关技术博客和分析文章。我们还介绍了编辑器技术和编辑器技术所能给「可视化页面搭建」带来的破局和创新。在此基础上,我们更是从一个自研的公司级「可视化页面搭建系统」入手,从探索阶段到成熟阶段的演进历史进行了介绍。
事实上,「可视化页面搭建系统」的话题还远为结束:我们正在此方向上探索更多可能,「微组件/微前端」,「页面归因能力」、「no/low code 技术」、「自定义组件埋点以及 A/B 流量能力」、「运行时的组件构建和渲染方案」,甚至「Serveless」、「云端 IDE」等。后续我们将会继续产出相关文章,请读者持续关注:技术博客,我们也在广泛求贤。
回到文章开篇所提到的那个问题上:“前端开发的难点到底在什么地方?”,我想已有答案的开发者将持续优化答案,仍然未知的开发者很快将会找到自己的答案。
Happy coding!
