

阅读本篇可能需要的预备知识《View的工作原理》、《Handler:Android消息机制》、《Window和WindowManager》、《Activity的启动过程详解》
一、背景和疑问
在Android中,当我们谈到 布局优化、卡顿优化 时,通常都知道 需要减少布局层级、减少主线程耗时操作,这样可以减少丢帧。如果丢帧比较严重,那么界面可能会有明显的卡顿感。我们知道 通常手机刷新是每秒60次,即每隔16.6ms刷新一次。 问题来了:
- 丢帧(掉帧) ,是说 这一帧延迟显示 还是丢弃不再显示 ?
- 布局层级较多/主线程耗时 是如何造成 丢帧的呢?
- 16.6ms刷新一次 是啥意思?是每16.6ms都走一次 measure/layout/draw ?
- measure/layout/draw 走完,界面就立刻刷新了吗?
- 如果界面没动静止了,还会刷新吗?
- 可能你知道VSYNC,这个具体指啥?在屏幕刷新中如何工作的?
- 可能你还听过屏幕刷新使用 双缓存、三缓存,这又是啥意思呢?
- 可能你还听过神秘的Choreographer,这又是干啥的?
小朋友,你是否有很多问号?
本文介绍的内容会详细解释以上问题,并在最后给解答。稳住,别慌~
二、显示系统基础知识
在一个典型的显示系统中,一般包括CPU、GPU、Display三个部分, CPU负责计算帧数据,把计算好的数据交给GPU,GPU会对图形数据进行渲染,渲染好后放到buffer(图像缓冲区)里存起来,然后Display(屏幕或显示器)负责把buffer里的数据呈现到屏幕上。如下图:
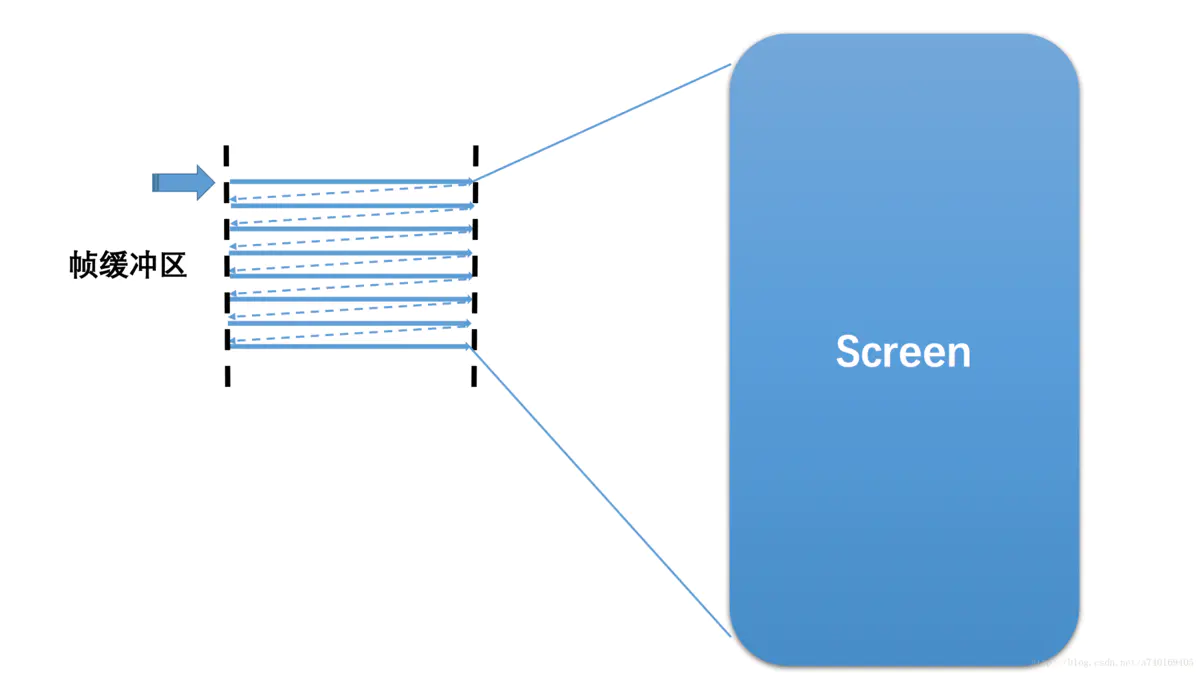
2.1 基础概念
-
屏幕刷新频率 一秒内屏幕刷新的次数(一秒内显示了多少帧的图像),单位 Hz(赫兹),如常见的 60 Hz。刷新频率取决于硬件的固定参数(不会变的)。
-
逐行扫描 显示器并不是一次性将画面显示到屏幕上,而是从左到右边,从上到下逐行扫描,顺序显示整屏的一个个像素点,不过这一过程快到人眼无法察觉到变化。以 60 Hz 刷新率的屏幕为例,这一过程即 1000 / 60 ≈ 16ms。
-
帧率 (Frame Rate) 表示 GPU 在一秒内绘制操作的帧数,单位 fps。例如在电影界采用 24 帧的速度足够使画面运行的非常流畅。而 Android 系统则采用更加流程的 60 fps,即每秒钟GPU最多绘制 60 帧画面。帧率是动态变化的,例如当画面静止时,GPU 是没有绘制操作的,屏幕刷新的还是buffer中的数据,即GPU最后操作的帧数据。
-
画面撕裂(tearing) 一个屏幕内的数据来自2个不同的帧,画面会出现撕裂感,如下图

2.2 双缓存
2.2.1 画面撕裂 原因
屏幕刷新频是固定的,比如每16.6ms从buffer取数据显示完一帧,理想情况下帧率和刷新频率保持一致,即每绘制完成一帧,显示器显示一帧。但是CPU/GPU写数据是不可控的,所以会出现buffer里有些数据根本没显示出来就被重写了,即buffer里的数据可能是来自不同的帧的, 当屏幕刷新时,此时它并不知道buffer的状态,因此从buffer抓取的帧并不是完整的一帧画面,即出现画面撕裂。
简单说就是Display在显示的过程中,buffer内数据被CPU/GPU修改,导致画面撕裂。
2.2.2 双缓存
那咋解决画面撕裂呢? 答案是使用 双缓存。
由于图像绘制和屏幕读取 使用的是同个buffer,所以屏幕刷新时可能读取到的是不完整的一帧画面。
双缓存,让绘制和显示器拥有各自的buffer:GPU 始终将完成的一帧图像数据写入到 Back Buffer,而显示器使用 Frame Buffer,当屏幕刷新时,Frame Buffer 并不会发生变化,当Back buffer准备就绪后,它们才进行交换。如下图:
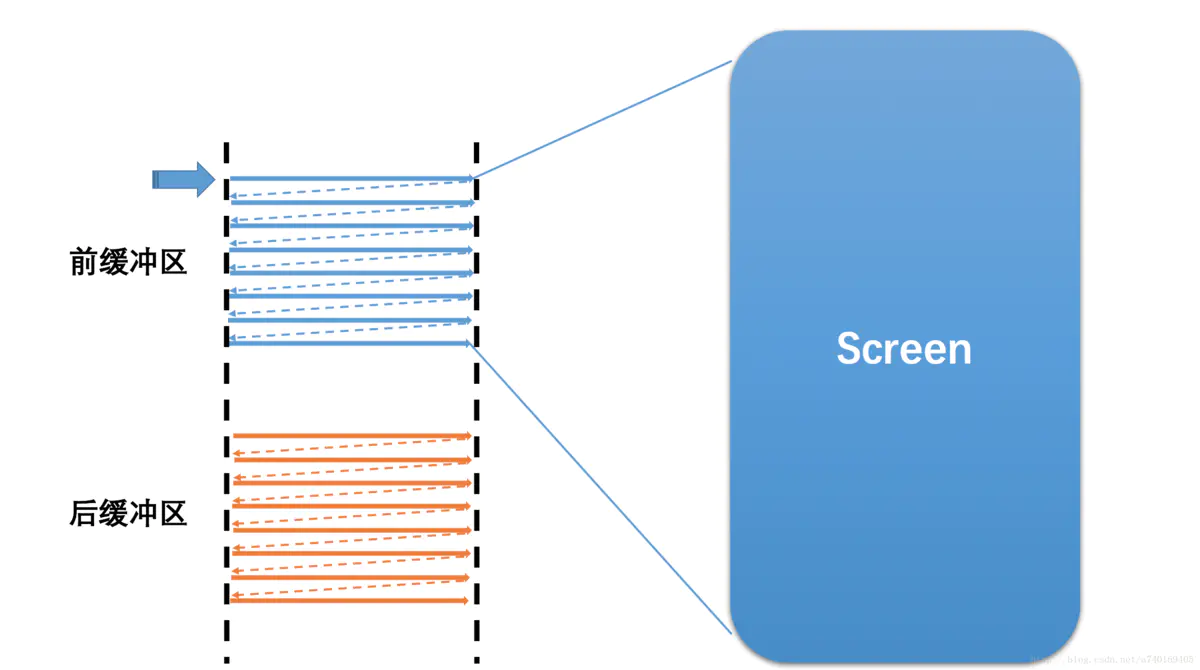
2.2.3 VSync
问题又来了:什么时候进行两个buffer的交换呢?
假如是 Back buffer准备完成一帧数据以后就进行,那么如果此时屏幕还没有完整显示上一帧内容的话,肯定是会出问题的。看来只能是等到屏幕处理完一帧数据后,才可以执行这一操作了。
当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时有一段时间空隙,称为VerticalBlanking Interval(VBI)。那,这个时间点就是我们进行缓冲区交换的最佳时间。因为此时屏幕没有在刷新,也就避免了交换过程中出现 screen tearing的状况。
VSync(垂直同步)是VerticalSynchronization的简写,它利用VBI时期出现的vertical sync pulse(垂直同步脉冲)来保证双缓冲在最佳时间点才进行交换。另外,交换是指各自的内存地址,可以认为该操作是瞬间完成。
所以说V-sync这个概念并不是Google首创的,它在早年的PC机领域就已经出现了。
三、Android屏幕刷新机制
3.1 Android4.1之前的问题
具体到Android中,在Android4.1之前,屏幕刷新也遵循 上面介绍的 双缓存+VSync 机制。如下图:
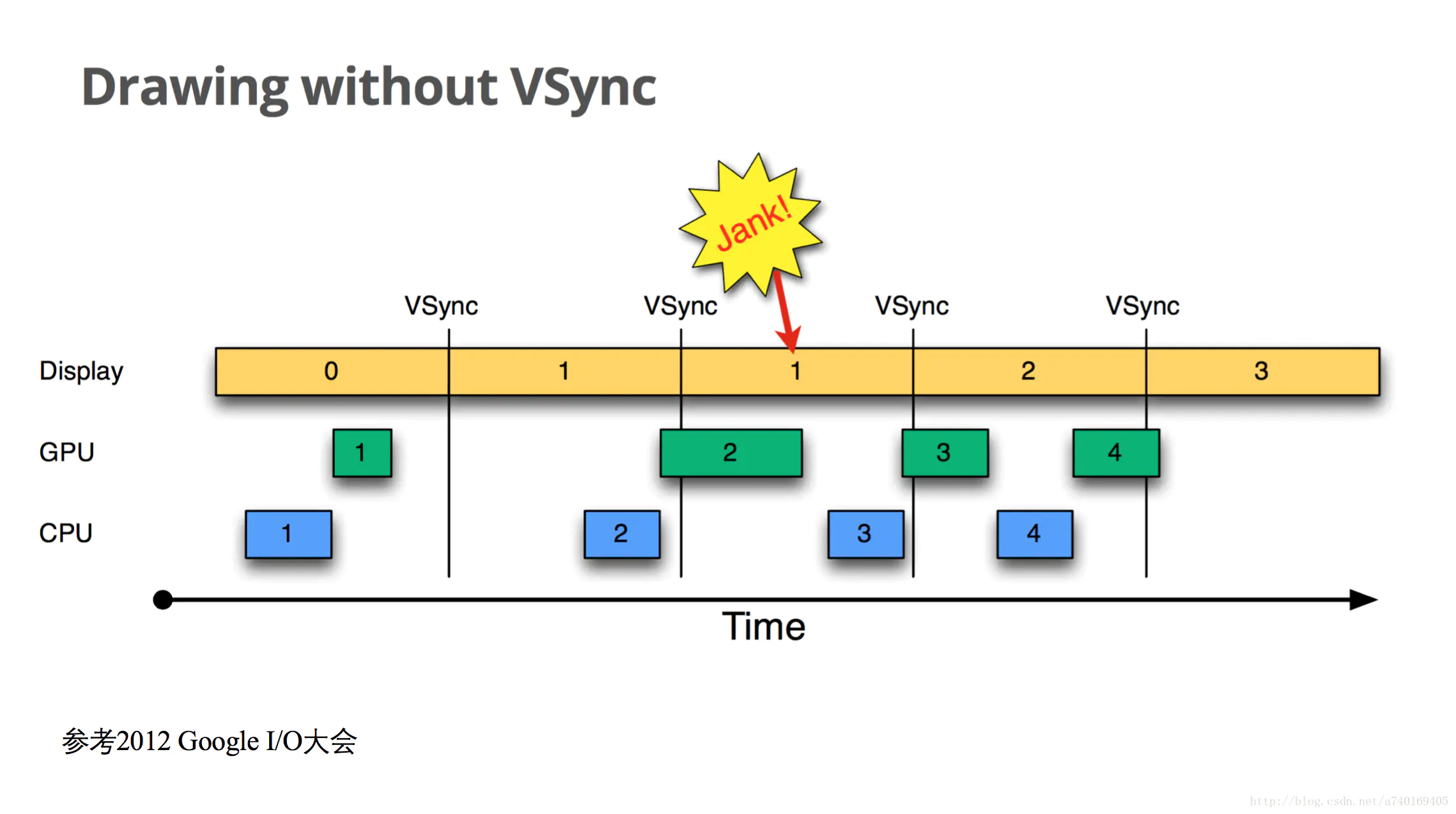
以时间的顺序来看下将会发生的过程:
- Display显示第0帧数据,此时CPU和GPU渲染第1帧画面,且在Display显示下一帧前完成
- 因为渲染及时,Display在第0帧显示完成后,也就是第1个VSync后,缓存进行交换,然后正常显示第1帧
- 接着第2帧开始处理,是直到第2个VSync快来前才开始处理的。
- 第2个VSync来时,由于第2帧数据还没有准备就绪,缓存没有交换,显示的还是第1帧。这种情况被Android开发组命名为“Jank”,即发生了丢帧。
- 当第2帧数据准备完成后,它并不会马上被显示,而是要等待下一个VSync 进行缓存交换再显示。
所以总的来说,就是屏幕平白无故地多显示了一次第1帧。
原因是 第2帧的CPU/GPU计算 没能在VSync信号到来前完成 。
我们知道,双缓存的交换 是在Vsyn到来时进行,交换后屏幕会取Frame buffer内的新数据,而实际 此时的Back buffer 就可以供GPU准备下一帧数据了。 如果 Vsyn到来时 CPU/GPU就开始操作的话,是有完整的16.6ms的,这样应该会基本避免jank的出现了(除非CPU/GPU计算超过了16.6ms)。 那如何让 CPU/GPU计算在 Vsyn到来时进行呢?
3.2 drawing with VSync
为了优化显示性能,Google在Android 4.1系统中对Android Display系统进行了重构,实现了Project Butter(黄油工程):系统在收到VSync pulse后,将马上开始下一帧的渲染。即一旦收到VSync通知(16ms触发一次),CPU和GPU 才立刻开始计算然后把数据写入buffer。如下图:
 CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。
CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。
一句话总结,VSync同步使得CPU/GPU充分利用了16.6ms时间,减少jank。
问题又来了,如果界面比较复杂,CPU/GPU的处理时间较长 超过了16.6ms呢?如下图:
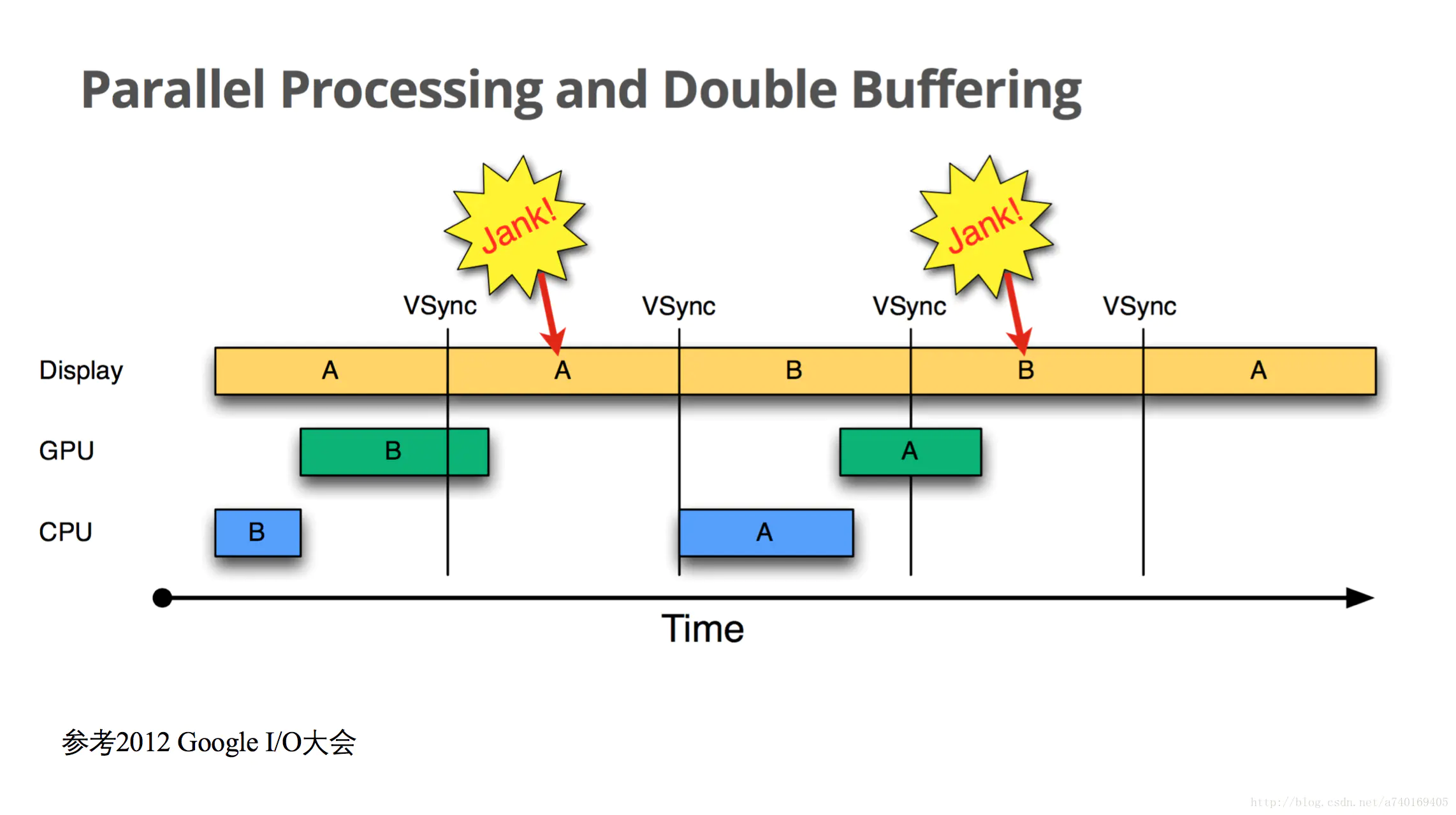
- 在第二个时间段内,但却因 GPU 还在处理 B 帧,缓存没能交换,导致 A 帧被重复显示。
- 而B完成后,又因为缺乏VSync pulse信号,它只能等待下一个signal的来临。于是在这一过程中,有一大段时间是被浪费的。
- 当下一个VSync出现时,CPU/GPU马上执行操作(A帧),且缓存交换,相应的显示屏对应的就是B。这时看起来就是正常的。只不过由于执行时间仍然超过16ms,导致下一次应该执行的缓冲区交换又被推迟了——如此循环反复,便出现了越来越多的“Jank”。
为什么 CPU 不能在第二个 16ms 处理绘制工作呢?
原因是只有两个 buffer,Back buffer正在被GPU用来处理B帧的数据, Frame buffer的内容用于Display的显示,这样两个buffer都被占用,CPU 则无法准备下一帧的数据。 那么,如果再提供一个buffer,CPU、GPU 和显示设备都能使用各自的buffer工作,互不影响。
3.3 三缓存
三缓存就是在双缓冲机制基础上增加了一个 Graphic Buffer 缓冲区,这样可以最大限度的利用空闲时间,带来的坏处是多使用的一个 Graphic Buffer 所占用的内存。

-
第一个Jank,是不可避免的。但是在第二个 16ms 时间段,CPU/GPU 使用 第三个 Buffer 完成C帧的计算,虽然还是会多显示一次 A 帧,但后续显示就比较顺畅了,有效避免 Jank 的进一步加剧。
-
注意在第3段中,A帧的计算已完成,但是在第4个vsync来的时候才显示,如果是双缓冲,那在第三个vynsc就可以显示了。
三缓冲有效利用了等待vysnc的时间,减少了jank,但是带来了延迟。 所以,是不是 Buffer 越多越好呢?这个是否定的,Buffer 正常还是两个,当出现 Jank 后三个足以。
以上就是Android屏幕刷新的原理了。
四、Choreographer
4.1 概述
上面讲到,Google在Android 4.1系统中对Android Display系统进行了优化:在收到VSync pulse后,将马上开始下一帧的渲染。即一旦收到VSync通知,CPU和GPU就立刻开始计算然后把数据写入buffer。本节就来讲 "drawing with VSync" 的实现——Choreographer。
- Choreographer,意为 舞蹈编导、编舞者。在这里就是指 对CPU/GPU绘制的指导—— 收到VSync信号 才开始绘制,保证绘制拥有完整的16.6ms,避免绘制的随机性。
- Choreographer,是一个Java类,包路径android.view.Choreographer。类注释是“协调动画、输入和绘图的计时”。
- 通常 应用层不会直接使用Choreographer,而是使用更高级的API,例如动画和View绘制相关的ValueAnimator.start()、View.invalidate()等。
- 业界一般通过Choreographer来监控应用的帧率。
4.2 源码分析
学习 Choreographer 可以帮助理解 每帧运行的原理,也可加深对 Handler机制、View绘制流程的理解,这样再去做UI优化、卡顿优化,思路会更清晰。
好了,下面开始源码分析了~
4.2.1 入口 和 实例创建
在《Window和WindowManager》、《Activity的启动过程详解》中介绍过,Activity启动 走完onResume方法后,会进行window的添加。window添加过程会 调用ViewRootImpl的setView()方法,setView()方法会调用requestLayout()方法来请求绘制布局,requestLayout()方法内部又会走到scheduleTraversals()方法,最后会走到performTraversals()方法,接着到了我们熟知的测量、布局、绘制三大流程了。
另外,查看源码发现,当我们使用 ValueAnimator.start()、View.invalidate()时,最后也是走到ViewRootImpl的scheduleTraversals()方法。(View.invalidate()内部会循环获取ViewParent直到ViewRootImpl的invalidateChildInParent()方法,然后走到scheduleTraversals(),可自行查看源码 )
即 所有UI的变化都是走到ViewRootImpl的scheduleTraversals()方法。
那么问题又来了,scheduleTraversals() 到 performTraversals() 中间 经历了什么呢?是立刻执行吗?答案很显然是否定的,根据我们上面的介绍,在VSync信号到来时才会执行绘制,即performTraversals()方法。 下面来瞅瞅这是如何实现的:
//ViewRootImpl.java
void scheduleTraversals() {
if (!mTraversalScheduled) {
//此字段保证同时间多次更改只会刷新一次,例如TextView连续两次setText(),也只会走一次绘制流程
mTraversalScheduled = true;
//添加同步屏障,屏蔽同步消息,保证VSync到来立即执行绘制
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
//mTraversalRunnable是TraversalRunnable实例,最终走到run(),也即doTraversal();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
final TraversalRunnable mTraversalRunnable = new TraversalRunnable();
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
//移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
...
//开始三大绘制流程
performTraversals();
...
}
}
主要有以下逻辑:
- 首先使用mTraversalScheduled字段保证同时间多次更改只会刷新一次,例如TextView连续两次setText(),也只会走一次绘制流程。
- 然后把当前线程的消息队列Queue添加了同步屏障,这样就屏蔽了正常的同步消息,保证VSync到来后立即执行绘制,而不是要等前面的同步消息。后面会具体分析同步屏障和异步消息的代码逻辑。
- 调用了mChoreographer.postCallback()方法,发送一个会在下一帧执行的回调,即在下一个VSync到来时会执行TraversalRunnable-->doTraversal()--->performTraversals()-->绘制流程。
接下来,就是分析的重点——Choreographer。我们先看它的实例mChoreographer,是在ViewRootImpl的构造方法内使用Choreographer.getInstance()创建:
Choreographer mChoreographer;
//ViewRootImpl实例是在添加window时创建
public ViewRootImpl(Context context, Display display) {
...
mChoreographer = Choreographer.getInstance();
...
}
我们先来看看Choreographer.getInstance():
public static Choreographer getInstance() {
return sThreadInstance.get();
}
private static final ThreadLocal<Choreographer> sThreadInstance =
new ThreadLocal<Choreographer>() {
@Override
protected Choreographer initialValue() {
Looper looper = Looper.myLooper();
if (looper == null) {
//当前线程要有looper,Choreographer实例需要传入
throw new IllegalStateException("The current thread must have a looper!");
}
Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);
if (looper == Looper.getMainLooper()) {
mMainInstance = choreographer;
}
return choreographer;
}
};
看到这里 如你对Handler机制中looper比较熟悉的话,应该知道 Choreographer和Looper一样 是线程单例的。且当前线程要有looper,Choreographer实例需要传入。接着看看Choreographer构造方法:
private Choreographer(Looper looper, int vsyncSource) {
mLooper = looper;
//使用当前线程looper创建 mHandler
mHandler = new FrameHandler(looper);
//USE_VSYNC 4.1以上默认是true,表示 具备接受VSync的能力,这个接受能力就是FrameDisplayEventReceiver
mDisplayEventReceiver = USE_VSYNC
? new FrameDisplayEventReceiver(looper, vsyncSource)
: null;
mLastFrameTimeNanos = Long.MIN_VALUE;
// 计算一帧的时间,Android手机屏幕是60Hz的刷新频率,就是16ms
mFrameIntervalNanos = (long)(1000000000 / getRefreshRate());
// 创建一个链表类型CallbackQueue的数组,大小为5,
//也就是数组中有五个链表,每个链表存相同类型的任务:输入、动画、遍历绘制等任务(CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_TRAVERSAL)
mCallbackQueues = new CallbackQueue[CALLBACK_LAST + 1];
for (int i = 0; i <= CALLBACK_LAST; i++) {
mCallbackQueues[i] = new CallbackQueue();
}
// b/68769804: For low FPS experiments.
setFPSDivisor(SystemProperties.getInt(ThreadedRenderer.DEBUG_FPS_DIVISOR, 1));
}
代码中都有注释,创建了一个mHandler、VSync事件接收器mDisplayEventReceiver、任务链表数组mCallbackQueues。FrameHandler、FrameDisplayEventReceiver、CallbackQueue后面会一一说明。
4.2.2 安排任务—postCallback
回头看mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null)方法,注意到第一个参数是CALLBACK_TRAVERSAL,表示回调任务的类型,共有以下5种类型:
//输入事件,首先执行
public static final int CALLBACK_INPUT = 0;
//动画,第二执行
public static final int CALLBACK_ANIMATION = 1;
//插入更新的动画,第三执行
public static final int CALLBACK_INSETS_ANIMATION = 2;
//绘制,第四执行
public static final int CALLBACK_TRAVERSAL = 3;
//提交,最后执行,
public static final int CALLBACK_COMMIT = 4;
五种类型任务对应存入对应的CallbackQueue中,每当收到 VSYNC 信号时,Choreographer 将首先处理 INPUT 类型的任务,然后是 ANIMATION 类型,最后才是 TRAVERSAL 类型。
postCallback()内部调用postCallbackDelayed(),接着又调用postCallbackDelayedInternal(),来瞅瞅:
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
...
synchronized (mLock) {
// 当前时间
final long now = SystemClock.uptimeMillis();
// 加上延迟时间
final long dueTime = now + delayMillis;
//取对应类型的CallbackQueue添加任务
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
//立即执行
scheduleFrameLocked(now);
} else {
//延迟运行,最终也会走到scheduleFrameLocked()
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
首先取对应类型的CallbackQueue添加任务,action就是mTraversalRunnable,token是null。CallbackQueue的addCallbackLocked()就是把 dueTime、action、token组装成CallbackRecord后 存入CallbackQueue的下一个节点,具体代码比较简单,不再跟进。
然后注意到如果没有延迟会执行scheduleFrameLocked()方法,有延迟就会使用 mHandler发送MSG_DO_SCHEDULE_CALLBACK消息,并且注意到 使用msg.setAsynchronous(true)把消息设置成异步,这是因为前面设置了同步屏障,只有异步消息才会执行。我们看下mHandler的对这个消息的处理:
private final class FrameHandler extends Handler {
public FrameHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_DO_FRAME:
// 执行doFrame,即绘制过程
doFrame(System.nanoTime(), 0);
break;
case MSG_DO_SCHEDULE_VSYNC:
//申请VSYNC信号,例如当前需要绘制任务时
doScheduleVsync();
break;
case MSG_DO_SCHEDULE_CALLBACK:
//需要延迟的任务,最终还是执行上述两个事件
doScheduleCallback(msg.arg1);
break;
}
}
}
直接使用doScheduleCallback方法,看看:
void doScheduleCallback(int callbackType) {
synchronized (mLock) {
if (!mFrameScheduled) {
final long now = SystemClock.uptimeMillis();
if (mCallbackQueues[callbackType].hasDueCallbacksLocked(now)) {
scheduleFrameLocked(now);
}
}
}
}
发现也是走到这里,即延迟运行最终也会走到scheduleFrameLocked(),跟进看看:
private void scheduleFrameLocked(long now) {
if (!mFrameScheduled) {
mFrameScheduled = true;
//开启了VSYNC
if (USE_VSYNC) {
if (DEBUG_FRAMES) {
Log.d(TAG, "Scheduling next frame on vsync.");
}
//当前执行的线程,是否是mLooper所在线程
if (isRunningOnLooperThreadLocked()) {
//申请 VSYNC 信号
scheduleVsyncLocked();
} else {
// 若不在,就用mHandler发送消息到原线程,最后还是调用scheduleVsyncLocked方法
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);//异步
mHandler.sendMessageAtFrontOfQueue(msg);
}
} else {
// 如果未开启VSYNC则直接doFrame方法(4.1后默认开启)
final long nextFrameTime = Math.max(
mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);
if (DEBUG_FRAMES) {
Log.d(TAG, "Scheduling next frame in " + (nextFrameTime - now) + " ms.");
}
Message msg = mHandler.obtainMessage(MSG_DO_FRAME);
msg.setAsynchronous(true);//异步
mHandler.sendMessageAtTime(msg, nextFrameTime);
}
}
}
- 如果系统未开启 VSYNC 机制,此时直接发送 MSG_DO_FRAME 消息到 FrameHandler。注意查看上面贴出的 FrameHandler 代码,此时直接执行 doFrame 方法。
- Android 4.1 之后系统默认开启 VSYNC,在 Choreographer 的构造方法会创建一个 FrameDisplayEventReceiver,scheduleVsyncLocked 方法将会通过它申请 VSYNC 信号。
- isRunningOnLooperThreadLocked 方法,其内部根据 Looper 判断是否在原线程,否则发送消息到 FrameHandler。最终还是会调用 scheduleVsyncLocked 方法申请 VSYNC 信号。
到这里,FrameHandler的作用很明显里了:发送异步消息(因为前面设置了同步屏障)。有延迟的任务发延迟消息、不在原线程的发到原线程、没开启VSYNC的直接走 doFrame 方法取执行绘制。
4.2.3 申请和接受VSync
好了, 接着就看 scheduleVsyncLocked 方法是如何申请 VSYNC 信号的。猜测肯定申请 VSYNC 信号后,信号到来时也是走doFrame() 方法,doFrame()后面再看。先跟进scheduleVsyncLocked():
private void scheduleVsyncLocked() {
mDisplayEventReceiver.scheduleVsync();
}
很简单,调用mDisplayEventReceiver的scheduleVsync()方法,mDisplayEventReceiver是Choreographer构造方法中创建,是FrameDisplayEventReceiver 的实例。 FrameDisplayEventReceiver是 DisplayEventReceiver 的子类,DisplayEventReceiver 是一个 abstract class:
public DisplayEventReceiver(Looper looper, int vsyncSource) {
if (looper == null) {
throw new IllegalArgumentException("looper must not be null");
}
mMessageQueue = looper.getQueue();
// 注册VSYNC信号监听者
mReceiverPtr = nativeInit(new WeakReference<DisplayEventReceiver>(this), mMessageQueue,
vsyncSource);
mCloseGuard.open("dispose");
}
在 DisplayEventReceiver 的构造方法会通过 JNI 创建一个 IDisplayEventConnection 的 VSYNC 的监听者。
FrameDisplayEventReceiver的scheduleVsync()就是在 DisplayEventReceiver中:
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
// 申请VSYNC中断信号,会回调onVsync方法
nativeScheduleVsync(mReceiverPtr);
}
}
那么scheduleVsync()就是使用native方法nativeScheduleVsync()去申请VSYNC信号。这个native方法就看不了了,只需要知道VSYNC信号的接受回调是onVsync(),我们直接看onVsync():
/**
* 接收到VSync脉冲时 回调
* @param timestampNanos VSync脉冲的时间戳
* @param physicalDisplayId Stable display ID that uniquely describes a (display, port) pair.
* @param frame 帧号码,自增
*/
@UnsupportedAppUsage
public void onVsync(long timestampNanos, long physicalDisplayId, int frame) {
}
具体实现是在FrameDisplayEventReceiver中:
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
@Override
public void onVsync(long timestampNanos, long physicalDisplayId, int frame) {
// Post the vsync event to the Handler.
// The idea is to prevent incoming vsync events from completely starving
// the message queue. If there are no messages in the queue with timestamps
// earlier than the frame time, then the vsync event will be processed immediately.
// Otherwise, messages that predate the vsync event will be handled first.
long now = System.nanoTime();
if (timestampNanos > now) {
Log.w(TAG, "Frame time is " + ((timestampNanos - now) * 0.000001f)
+ " ms in the future! Check that graphics HAL is generating vsync "
+ "timestamps using the correct timebase.");
timestampNanos = now;
}
if (mHavePendingVsync) {
Log.w(TAG, "Already have a pending vsync event. There should only be "
+ "one at a time.");
} else {
mHavePendingVsync = true;
}
mTimestampNanos = timestampNanos;
mFrame = frame;
//将本身作为runnable传入msg, 发消息后 会走run(),即doFrame(),也是异步消息
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
onVsync()中,将接收器本身作为runnable传入异步消息msg,并使用mHandler发送msg,最终执行的就是doFrame()方法了。
注意一点是,onVsync()方法中只是使用mHandler发送消息到MessageQueue中,不一定是立刻执行,如何MessageQueue中前面有较为耗时的操作,那么就要等完成,才会执行本次的doFrame()。
4.2.4 doFrame
和上面猜测一样,申请VSync信号接收到后确实是走 doFrame()方法,那么就来看看Choreographer的doFrame():
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
return; // no work to do
}
...
// 预期执行时间
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
// 超时时间是否超过一帧的时间(这是因为MessageQueue虽然添加了同步屏障,但是还是有正在执行的同步任务,导致doFrame延迟执行了)
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
// 计算掉帧数
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
// 掉帧超过30帧打印Log提示
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
...
frameTimeNanos = startNanos - lastFrameOffset;
}
...
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
// Frame标志位恢复
mFrameScheduled = false;
// 记录最后一帧时间
mLastFrameTimeNanos = frameTimeNanos;
}
try {
// 按类型顺序 执行任务
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
}
上面都有注释了很好理解,接着看任务的具体执行doCallbacks 方法:
void doCallbacks(int callbackType, long frameTimeNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
final long now = System.nanoTime();
// 根据指定的类型CallbackkQueue中查找到达执行时间的CallbackRecord
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(now / TimeUtils.NANOS_PER_MS);
if (callbacks == null) {
return;
}
mCallbacksRunning = true;
//提交任务类型
if (callbackType == Choreographer.CALLBACK_COMMIT) {
final long jitterNanos = now - frameTimeNanos;
if (jitterNanos >= 2 * mFrameIntervalNanos) {
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos
+ mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Commit callback delayed by " + (jitterNanos * 0.000001f)
+ " ms which is more than twice the frame interval of "
+ (mFrameIntervalNanos * 0.000001f) + " ms! "
+ "Setting frame time to " + (lastFrameOffset * 0.000001f)
+ " ms in the past.");
mDebugPrintNextFrameTimeDelta = true;
}
frameTimeNanos = now - lastFrameOffset;
mLastFrameTimeNanos = frameTimeNanos;
}
}
}
try {
// 迭代执行队列所有任务
for (CallbackRecord c = callbacks; c != null; c = c.next) {
// 回调CallbackRecord的run,其内部回调Callback的run
c.run(frameTimeNanos);
}
} finally {
synchronized (mLock) {
mCallbacksRunning = false;
do {
final CallbackRecord next = callbacks.next;
//回收CallbackRecord
recycleCallbackLocked(callbacks);
callbacks = next;
} while (callbacks != null);
}
}
}
主要内容就是取对应任务类型的队列,遍历队列执行所有任务,执行任务是 CallbackRecord的 run 方法:
private static final class CallbackRecord {
public CallbackRecord next;
public long dueTime;
public Object action; // Runnable or FrameCallback
public Object token;
@UnsupportedAppUsage
public void run(long frameTimeNanos) {
if (token == FRAME_CALLBACK_TOKEN) {
// 通过postFrameCallback 或 postFrameCallbackDelayed,会执行这里
((FrameCallback)action).doFrame(frameTimeNanos);
} else {
//取出Runnable执行run()
((Runnable)action).run();
}
}
}
前面看到mChoreographer.postCallback传的token是null,所以取出action,就是Runnable,执行run(),这里的action就是 ViewRootImpl 发起的绘制任务mTraversalRunnable了,那么这样整个逻辑就闭环了。
那么 啥时候 token == FRAME_CALLBACK_TOKEN 呢?答案是Choreographer的postFrameCallback()方法:
public void postFrameCallback(FrameCallback callback) {
postFrameCallbackDelayed(callback, 0);
}
public void postFrameCallbackDelayed(FrameCallback callback, long delayMillis) {
if (callback == null) {
throw new IllegalArgumentException("callback must not be null");
}
//也是走到是postCallbackDelayedInternal,并且注意是CALLBACK_ANIMATION类型,
//token是FRAME_CALLBACK_TOKEN,action就是FrameCallback
postCallbackDelayedInternal(CALLBACK_ANIMATION,
callback, FRAME_CALLBACK_TOKEN, delayMillis);
}
public interface FrameCallback {
public void doFrame(long frameTimeNanos);
}
可以看到postFrameCallback()传入的是FrameCallback实例,接口FrameCallback只有一个doFrame()方法。并且也是走到postCallbackDelayedInternal,FrameCallback实例作为action传入,token则是FRAME_CALLBACK_TOKEN,并且任务是CALLBACK_ANIMATION类型。
Choreographer的postFrameCallback()通常用来计算丢帧情况,使用方式如下:
//Application.java
public void onCreate() {
super.onCreate();
//在Application中使用postFrameCallback
Choreographer.getInstance().postFrameCallback(new FPSFrameCallback(System.nanoTime()));
}
public class FPSFrameCallback implements Choreographer.FrameCallback {
private static final String TAG = "FPS_TEST";
private long mLastFrameTimeNanos = 0;
private long mFrameIntervalNanos;
public FPSFrameCallback(long lastFrameTimeNanos) {
mLastFrameTimeNanos = lastFrameTimeNanos;
mFrameIntervalNanos = (long)(1000000000 / 60.0);
}
@Override
public void doFrame(long frameTimeNanos) {
//初始化时间
if (mLastFrameTimeNanos == 0) {
mLastFrameTimeNanos = frameTimeNanos;
}
final long jitterNanos = frameTimeNanos - mLastFrameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if(skippedFrames>30){
//丢帧30以上打印日志
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
}
mLastFrameTimeNanos=frameTimeNanos;
//注册下一帧回调
Choreographer.getInstance().postFrameCallback(this);
}
}
4.2.5 小结
使用Choreographer的postCallback()、postFrameCallback() 作用理解:发送任务 存队列中,监听VSync信号,当前VSync到来时 会使用mHandler发送异步message,这个message的Runnable就是队列中的所有任务。
好了,Choreographer整个代码逻辑都讲完了,引用《Android 之 Choreographer 详细分析》的流程图:

五、Handler异步消息与同步屏障
最后来介绍下异步消息与同步屏障。
在Handler中,Message分为3种:同步消息、异步消息、同步屏障消息,他们三者都是Message,只是属性有些区别。
5.1异步消息
通常我们使用创建Handler方式如下:
public Handler() {
this(null, false);
}
注意到内部使用了两个两个参数的构造方法,其中第二个是false:
public Handler(@Nullable Callback callback, boolean async) {
...
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
//异步标志
mAsynchronous = async;
}
这个false就表示 非异步,即使用的是同步消息,mAsynchronous使用是在enqueueMessage()中:
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
//将Handler赋值给Message的target变量
msg.target = this;
//mAsynchronous为false,为同步消息
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
这里如果mAsynchronous是true,就会使用msg.setAsynchronous(true)设置为异步消息。所以上面Choreographer中使用的都是异步消息。
5.2同步屏障消息
postSyncBarrier()方法就是用来插入一个屏障到消息队列的,
//MessageQueue
public int postSyncBarrier() {
return postSyncBarrier(SystemClock.uptimeMillis());
}
private int postSyncBarrier(long when) {
synchronized (this) {
final int token = mNextBarrierToken++;
//注意这里 没有tartget赋值
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
Message prev = null;
Message p = mMessages;
if (when != 0) {
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
}
if (prev != null) { // invariant: p == prev.next
msg.next = p;
prev.next = msg;
} else {
msg.next = p;
mMessages = msg;
}
return token;
}
}
可以看到它很简单,从这个方法我们可以知道如下:
- 屏障消息和普通消息的区别在于屏障没有tartget,普通消息有target是因为它需要将消息分发给对应的target,而屏障不需要被分发,它就是用来挡住普通消息来保证异步消息优先处理的。
- 屏障和普通消息一样可以根据时间来插入到消息队列中的适当位置,并且只会挡住它后面的同步消息的分发
- postSyncBarrier()返回一个int类型的数值,通过这个数值可以撤销屏障即removeSyncBarrier()。
- postSyncBarrier()是私有的,如果我们想调用它就得使用反射。插入普通消息会唤醒消息队列,但是插入屏障不会。
5.3 原理
同步屏障消息 是如何 挡住普通消息来保证异步消息优先处理的?我们看看MessageQueue的next()方法:
//MessageQueue.java
Message next() {
...
for (;;) {
...
synchronized (this) {
// Try to retrieve the next message. Return if found.
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// msg.target == null 就是同步屏障消息,那么只取异步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
...
}
}
很简单,遍历消息队列时,发现了同步屏障消息,那么就只取异步消息了。
好了,相关知识终于讲完了。
六、疑问解答
- 丢帧(掉帧) ,是说 这一帧延迟显示 还是丢弃不再显示 ? 答:延迟显示,因为缓存交换的时机只能等下一个VSync了。
- 布局层级较多/主线程耗时 是如何造成 丢帧的呢? 答:布局层级较多/主线程耗时 会影响CPU/GPU的执行时间,大于16.6ms时只能等下一个VSync了。
- 16.6ms刷新一次 是啥意思?是每16.6ms都走一次 measure/layout/draw ? 答:屏幕的固定刷新频率是60Hz,即16.6ms。不是每16.6ms都走一次 measure/layout/draw,而是有绘制任务才会走,并且绘制时间间隔是取决于布局复杂度及主线程耗时。
- measure/layout/draw 走完,界面就立刻刷新了吗? 答:不是。measure/layout/draw 走完后 会在VSync到来时进行缓存交换和刷新。
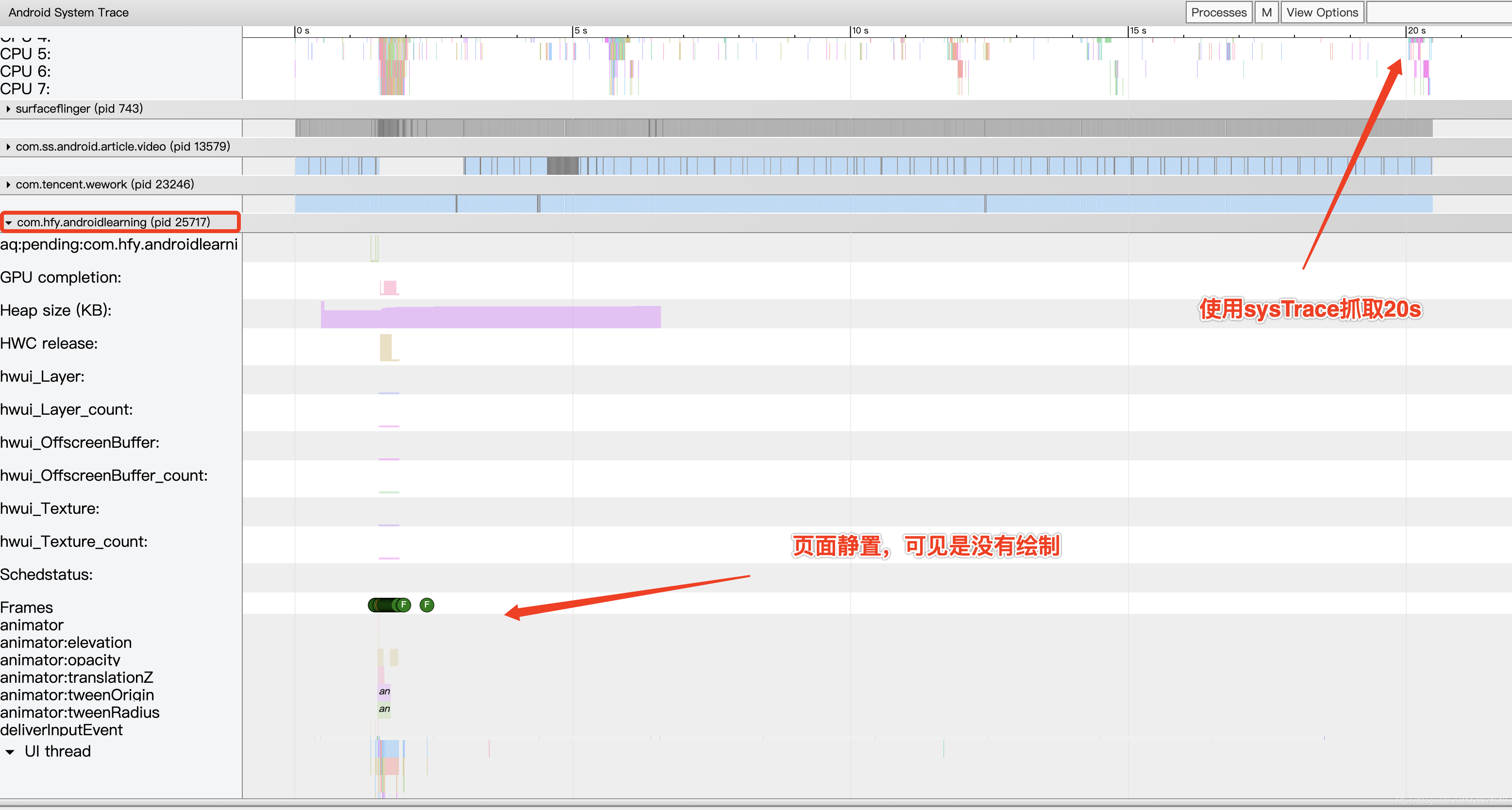
- 如果界面没动静止了,还会刷新吗? 答:屏幕会固定每16.6ms刷新,但CPU/GPU不走绘制流程。见下面的SysTrace图。
- 可能你知道VSYNC,这个具体指啥?在屏幕刷新中如何工作的? 答:当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时会出现的vertical sync pulse(垂直同步脉冲)来保证双缓冲在最佳时间点才进行交换。并且Android4.1后 CPU/GPU的绘制是在VSYNC到来时开始。
- 可能你还听过屏幕刷新使用 双缓存、三缓存,这又是啥意思呢? 答:双缓存是Back buffer、Frame buffer,用于解决画面撕裂。三缓存增加一个Back buffer,用于减少Jank。
- 可能你还听过神秘的Choreographer,这又是干啥的? 答:用于实现——"CPU/GPU的绘制是在VSYNC到来时开始"。
好了,就到这里了。以上问题都理解的话,会对Android屏幕刷新、UI优化、卡顿优化 有更加全面和清晰的认识。其中涉及的知识点也较多,需要把这些都串起来。
.
参考与感谢
.
你的 点赞、评论、收藏、转发,是对我的巨大鼓励!
欢迎关注我的 公 众 号:
