

接触Flink一段时间了,遇到了一些问题,其中有一个checkpoint失败导致作业重启的问题,遇到了很多次,重启之后一般也能恢复正常,没有太在意,最近2天有同事又频繁遇到,这里记录一下解决方案和分析过程。
我们的flink测试环境有3个节点,部署架构是每个flink节点上部署一个HDFS的DataNode节点,hdfs用于flink的checkpoint和savepoint
现象

看日志是说有个3个datanode活着,文件副本是1,但是写文件失败
There are 3 datanode(s) running and no node(s) are excluded
网上搜了一下这种报错,没有直接的答案,我看了下namenode的日志,没有更多直接的信息
50070 web ui上看一切正常,datanode的剩余空间都还有很多,使用率不到10%
我试了一下往hdfs上put一个文件再get下来,都ok,说明hdfs服务没有问题,datanode也是通的
日志现象1
继续前后翻了一下namenode的日志,注意到有一些warning信息,
这时候怀疑块放置策略有问题

按照日志提示打开相应的的debug开关
修改
etc/hadoop/log4j.properties
找到
log4j.logger.org.apache.hadoop.fs.s3a.S3AFileSystem=WARN
照抄这个格式,在下面添加
log4j.logger.org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy=DEBUG
log4j.logger.org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor=DEBUG
log4j.logger.org.apache.hadoop.net.NetworkTopology=DEBUG
重启namenode,然后重跑flink作业
日志现象2
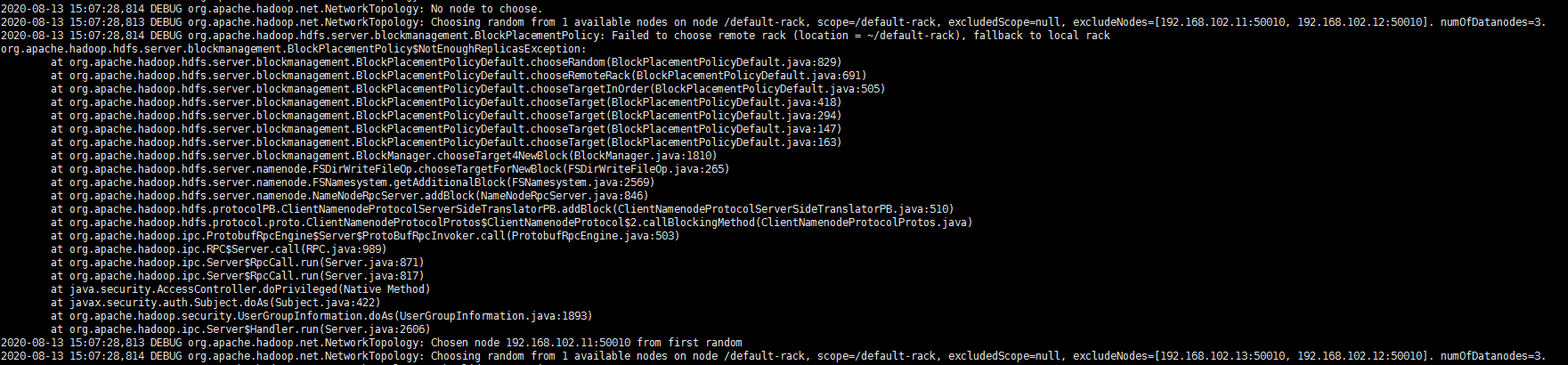
这时候看到的问题是机架感知策略无法满足,因为我们没有提供机架映射脚本,默认同一个机架,但是仔细想想跟这个应该也没有关系
因为很多生产环境的hdfs其实都不配置机架映射脚本,并且导致checkpoint失败的问题并不是一直存在,最起码put/get文件都是正常的。
这时候开始考虑看一下hdfs的源码了,根据上面的日志调用栈,先看到BlockPlacementPolicyDefault以及相关的DatanodeDescriptor
这些源码大致的意思是当给一个块选择一个datanode的时候,要对这个datanode进行一些检查,比如看下剩余空间,看下繁忙程度
当我们的问题复现的时候,观察日志会发现一些与此相关的关键信息


这个日志的意思是,存储空间有43G,分配块实际需要100多M,但是scheduled大小就超过43G,因此我们认为正常的datanode,namenode认为它空间不足了
原因
scheduled大小含义是什么呢? 根据代码可以看到scheduled大小是块大小跟一个计数器做乘法,计数器代表的其实是新建文件块数量计数器,hdfs根据这两个参数评估可能需要的存储空间,相当于给每个datanode预定了一定的空间,预定的空间在文件写入后,计算完真实的占用空间后,还会调整回来。
了解这个原理之后,可以判断的是datanode在一段时间内被预定了太多的空间。
flink的checkpoint机制可以参考这一篇www.jianshu.com/p/9c587bd49…
大致的意思是taskmanager上的很多任务线程都会写hdfs
看了下hdfs的目录结构,有大量的类似uuid命名checkpoint文件,同时每个文件都很小
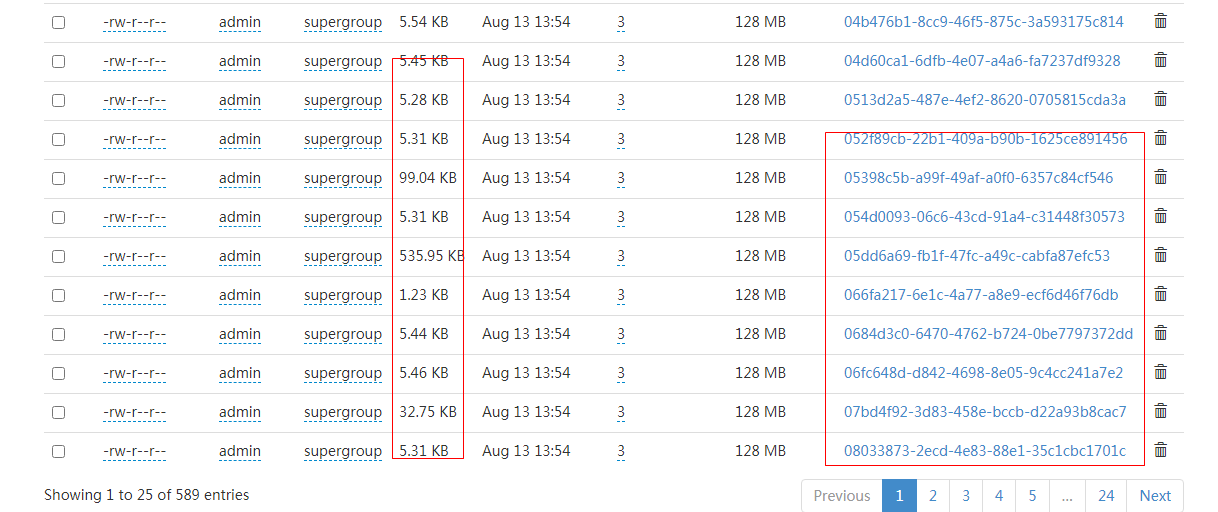
当我们的作业并发较大时,相应的在hdfs上就会创建更多的checkpoint文件,尽管我们的文件大小只有几K,但是在每一个datanode预定的空间都是128M乘以分配到的文件数量(文件很小,不超过128M),那么43G的空间,最多预定多少文件呢?除一下也就是300多个,三个节点也就是最多900个,我们有多个作业,总并发较大,在预留空间完全释放前,是很容易出现这个问题的。
之前知道hdfs不适合存储小文件,原因是大量小文件会导致inode消耗以及block location这些元数据增长,让namenode内存吃紧,这个例子还表明
当blocksize设置较大,文件大小却远小于blocksize时,大量这种小文件会导致datanode直接"不可用"。
解决办法
块大小不是集群属性,是文件属性,客户端可以设置的,flink这时候每个taskmanager和jobmanager都是hdfs的"客户端",根据flink文档,我们可以做如下配置
1、在conf/flink-conf.yaml中指定一个hdfs的配置文件路径
fs.hdfs.hadoopconf: /home/xxxx/flink/conf
这里跟flink的配置文件路径选择同一个目录
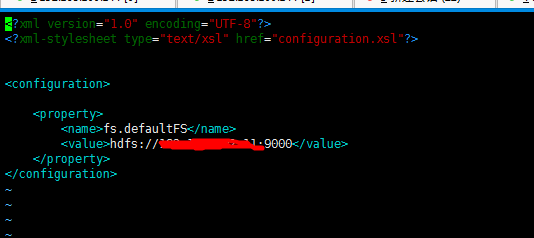
2、放进去2个配置文件,一个core-site.xml一个是hdfs-site.xml
core-site.xml可以不放,如果checkpoint和savepoint指定了具体的hdfs地址的话,
hdfs-site.xml里加上blockSize配置即可,比如这里我们给它设置为1M
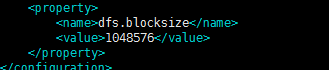
具体块大小如何设置,需要观察自己的作业状态文件大小自己灵活调整。
重启flink集群,提交作业即可,运行时可以观察下hdfs的fsimage大小,注意不要因为块太小,小文件太多导致元数据过大。
小结
我们已经将该问题同步到集群自动化部署脚本中,部署时会专门添加blocksize的配置。
flink这套依赖hdfs的checkpoint方案对于轻量级的流计算场景稍显臃肿,checkpoint的分布式存储不管是直接filesystem还是rocksDB都需要hdfs,其实从checkpoint原理和数据类型考虑,es应该也是不错的选择,遗憾的是社区并没有提供这种方案。
欢迎关注我的公众号:【 Java烂猪皮 】,获得独家整理的学习资源、日常干货及福利赠送。
