

作者|Paul Hiemstra 编译|VK 来源|Towards Datas Science
你也可以在GitHub上阅读这篇文章。这个GitHub存储库包含你自己运行分析所需的一切:github.com/PaulHiemstr…
介绍
对于许多数据科学家来说,最基本的模型是多元线性回归。在许多分析中,它是第一个被调用的,并作为更复杂模型的基准。它的一个优点是容易解释得到的系数,这是神经网络特别难以解决的问题。
然而,线性回归并非没有挑战。在本文中,我们关注一个特殊的挑战:处理大量的特征。大数据集的具体问题是如何为模型选择相关的特征,如何克服过拟合以及如何处理相关特征。
正则化是一种非常有效的技术,有助于解决上述问题。正则化是通过用一个限制系数大小的项来扩展标准最小二乘目标或损失函数来实现的。本文的主要目的是让你熟悉正则化及其提供的优势。
在本文中,你将了解以下主题:
-
什么样的正则化更详细,为什么值得使用
-
有哪些不同类型的正则化,以及术语L1和L2正则化意味着什么
-
如何使用正则化
-
如何使用tsfresh生成正则化回归的特征
-
如何解释和可视化正则化回归系数
-
如何利用交叉验证优化正则化强度
-
如何可视化交叉验证的结果
我们将从更理论上介绍正则化开始本文,并以一个实际例子结束。
为什么使用正则化,什么是正则化
下图显示了一个绿色和蓝色的函数,与红色观察值相匹配。这两个函数都完美地符合观测值,我们该以何种方式选择这2个函数。
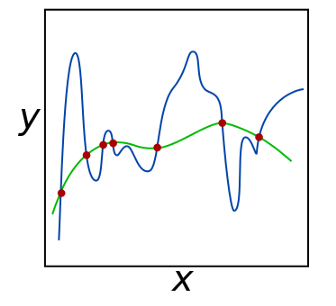
我们的问题是不确定的,这导致我们任意不能选择这两个函数中的任何一个。在回归分析中,有两个因素减低了性能:多重共线性(相关特征)和特征的数量。
通常可以手工以得到少量特征。然而,在更多的数据驱动方法中,我们通常使用许多特征,这导致特征之间有很多相关,而我们事先并不知道哪些特征会很好地工作。为了克服不确定性,我们需要在问题中添加信息。在我们的问题中添加信息的数学术语是正则化。
回归中执行正则化的一种非常常见的方法是用附加项扩展损失函数。Tibshirani(1997)提出用一种称为Lasso的方法将系数的总大小添加到损失函数中。表示系数总大小的数学方法是使用所谓的范数:
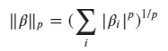
其中p值决定了我们使用什么样的正则化。p值为1称为L1范数,值为2称为L2范数等。既然我们有了范数的数学表达式,我们就可以扩展我们通常在回归中使用的最小二乘损失函数:
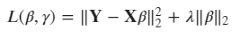
注意,这里我们使用L2范数,我们也用L2范数表示了损失函数的平方差部分。另外,lambda是正则化强度。正则化强度决定了系数大小与损失函数平方差部分的关系。注意,范数项主要优点是减少了模型中的方差。
包含L2范数的回归称为岭回归。岭回归减少了预测中的方差,使其更稳定,更不容易过拟合。此外,方差的减少还可以对抗多重共线性带来的方差。
当我们在损失函数中加入L1范数时,这称为Lasso。Lasso在减小系数大小方面比岭回归更进一步,会降到零。这实际上意味着变量从模型中退出,因此lasso是在执行特征选择。这在处理高度相关的特征(多重共线性)时有很大的影响。Lasso倾向于选择一个相关变量,而岭回归平衡所有特征。Lasso的特征选择在你有很多输入特征时特别有用,而你事先并不知道哪些特征会对模型有利。
如果要混合Lasso回归和岭回归,可以同时向损失函数添加L1和L2范数。这就是所谓的Elastic正则化。在理论部分结束后,让我们进入正则化的实际应用。
正则化的示例使用
用例
人类很善于识别声音。仅凭音频,我们就能够区分汽车、声音和枪支等事物。如果有人特别有经验,他们甚至可以告诉你什么样声音属于哪种汽车。在这种情况下,我们将建立一个正则化回归模型。
数据集
我们的数据是75个鼓样品,每种类型的鼓有25个:底鼓、圈套鼓和汤姆鼓。每个鼓样本存储在wav文件中,例如:
sample_rate, bass = wavfile.read('./sounds/bass1.wav')
bass_pd = pd.DataFrame(bass, columns=['left', 'right']).assign(time_id = range(len(bass)))
bass_pd.head()

# 注意,本文中的所有图形都使用了plotnine
(
ggplot(bass_pd.melt(id_vars = ['time_id'], value_name='amplitude', var_name='stereo'))
+ geom_line(aes(x = 'time_id',
y = 'amplitude'))
+ facet_wrap('stereo')
+ theme(figure_size=(4,2))
)
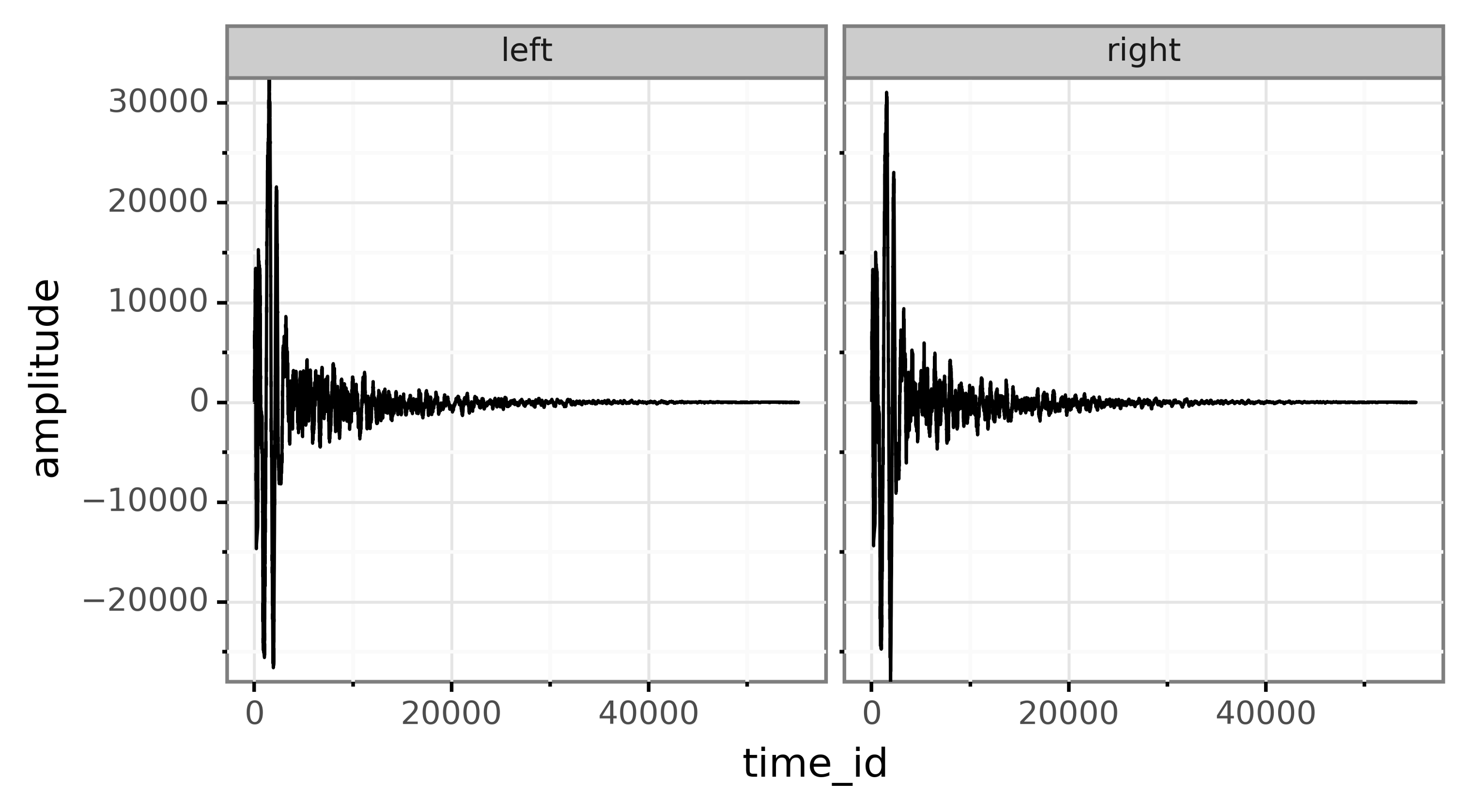
wav文件是立体声的,包含两个声道:左声道和右声道。该文件包含随时间变化的波形,在x轴上随时间变化,在y轴上包含振幅。振幅基本上列出了扬声器圆锥应该如何振动。
以下代码构造了一个包含所有75个鼓样本的数据帧:
import glob
wav_files = glob.glob('sounds/kick/*.wav') + glob.glob('sounds/snare/*.wav') + glob.glob('sounds/tom/*.wav')
all_audio = pd.concat([audio_to_dataframe(path) for path in wav_files])
all_labels = pd.Series(np.repeat(['kick', 'snare', 'tom'], 25),
index = wav_files)
all_audio.head()
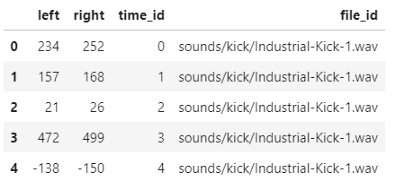
附加函数audio_to_dataframe可以在github仓库的helper_functions.py找到。
使用tsfresh生成特征
为了拟合一个监督模型,sklearn需要两个数据集:一个带有我们的特征的样本特征x矩阵(或数据帧)和一个带有标签的样本向量。
因为我们已经有了标签,所以我们把精力集中在特征矩阵上。因为我们希望我们的模型对每个声音文件进行预测,所以特征矩阵中的每一行都应该包含一个声音文件的所有特征。
接下来的挑战是提出我们想要使用的特征。例如,低音鼓的声音中可能有更多的低音频率。因此,我们可以在所有样本上运行FFT并将低音频率分离成一个特征。
采用这种手动特征工程方法可能会非常耗费人力,并且很有可能排除重要特征。tsfresh(docs)是一个Python包,它极大地加快了这个过程。该包基于timeseries数据生成数百个潜在的特征,还包括预选相关特征的方法。有数百个特征强调了在这种情况下使用某种正则化的重要性。
为了熟悉tsfresh,我们首先使用MinimalFCParameters设置生成少量特征:
from tsfresh import extract_relevant_features
from tsfresh.feature_extraction import MinimalFCParameters
settings = MinimalFCParameters()
audio_tsfresh_minimal = extract_relevant_features(all_audio, all_labels,
column_id='file_id', column_sort='time_id',
default_fc_parameters=settings)
print(audio_tsfresh_minimal.shape)
audio_tsfresh_minimal.head()
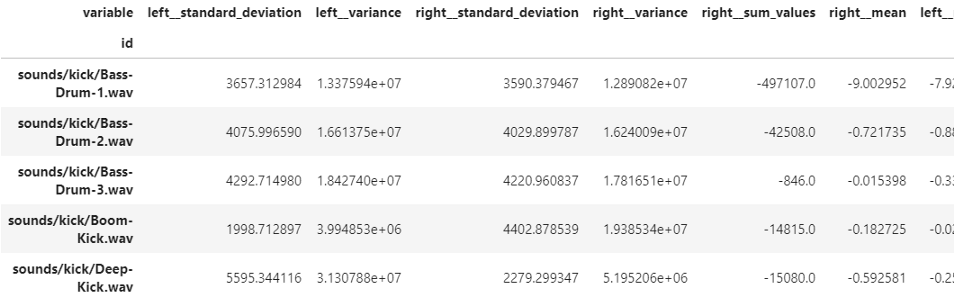
这就给我们留下了11个特征。我们使用extract_related_features函数来允许tsfresh根据标签和生成的潜在特征预先选择有意义的特征。在这种最小的情况下,tsfresh查看由file_id列标识的每个声音文件,并生成诸如振幅的标准偏差、平均振幅等特征。
但是tsfresh的强大之处在于我们产生了更多的特征。在这里,我们使用相关默认设置来节省一些时间,而不是使用完整的设置。注意,我直接读取了dataframe的pickle数据,它是使用github仓库中用generate_drum_model.py脚本生成的。我这样做是为了节省时间,因为在我的12线程机器上计算大约需要10分钟。
from tsfresh.feature_extraction import EfficientFCParameters
settings = EfficientFCParameters()
audio_tsfresh = pd.read_pickle('pkl/drum_tsfresh.pkl')
print(audio_tsfresh.shape)
audio_tsfresh.head()
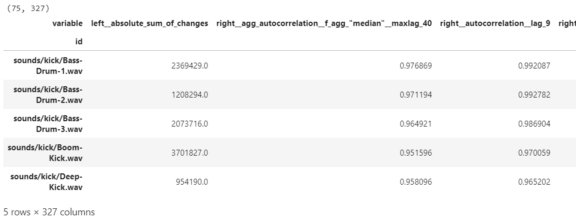
这使得特征的数量从11个扩展到327个。这些特征为我们的正则化回归模型提供了一个非常广阔的学习空间。
正则回归模型的拟合
现在我们已经有了一组输入特征和所需的标签,我们可以继续并拟合我们的正则化回归模型。我们使用来自sklearn的逻辑回归模型:
from sklearn.linear_model import LogisticRegression
base_log_reg = LogisticRegression(penalty='l1',
multi_class='ovr',
solver='saga',
tol=1e-6,
max_iter=int(1e4),
C=1)
并使用以下设置:
-
我们将惩罚设置为l1,即我们使用l1范数的正则化。
-
我们将multi_class设置为1 vs rest(ovr)。这意味着我们的模型由三个子模型组成,每种可能类型的鼓各有一个。当用整体模型进行预测时,我们只需选择表现最好的模型。
-
我们使用saga求解器来拟合我们的损失函数。还有更多可用的,但saga能够完成我们所需要的功能。
-
现在将C设为1,其中C等于
1/正则化强度。请注意,sklearn Lasso实现使用了𝛼,它等于1/2C。我发现𝛼是一个更直观的度量,我们将在本文的其余部分使用它。 -
tol和max_iter设置为可接受的默认值。
基于这些设置,我们进行了一些实验。首先,我们将比较基于少量和大量tsfresh特征的模型的性能。之后,我们将重点讨论如何使用交叉验证来拟合正则化强度,并对拟合模型的性能进行更全面的讨论。
最小tsfresh vs 有效tsfresh
我们的第一个分析测试了这样一个假设:使用更多生成的tsfresh特征可以得到更好的模型。为了测试这一点,我们使用最小tsfresh和有效tsfresh特征来拟合一个模型。我们通过模型在测试集上的准确性来判断模型的性能。我们重复20次,以了解由于在选择训练和测试集时的随机性而导致的精确度差异:
from sklearn.model_selection import train_test_split
def get_score(audio_data, labels):
# 用cross_val_score代替?
audio_train, audio_test, label_train, label_test = train_test_split(audio_data, labels, test_size=0.3)
log_reg = base_log_reg.fit(audio_train, label_train)
return log_reg.score(audio_test, label_test)
accuracy_minimal = [get_score(audio_tsfresh_minimal, all_labels) for x in range(20)]
accuracy_efficient = [get_score(audio_tsfresh, all_labels) for x in range(20)]
plot_data = pd.concat([pd.DataFrame({'accuracy': accuracy_minimal, 'tsfresh_data': 'minimal'}),
pd.DataFrame({'accuracy': accuracy_efficient, 'tsfresh_data': 'efficient'})])
(
ggplot(plot_data) + geom_boxplot(aes(x='tsfresh_data', y='accuracy')) +
coord_flip() +
labs(y = 'Accuracy', x = 'TSfresh setting')
)
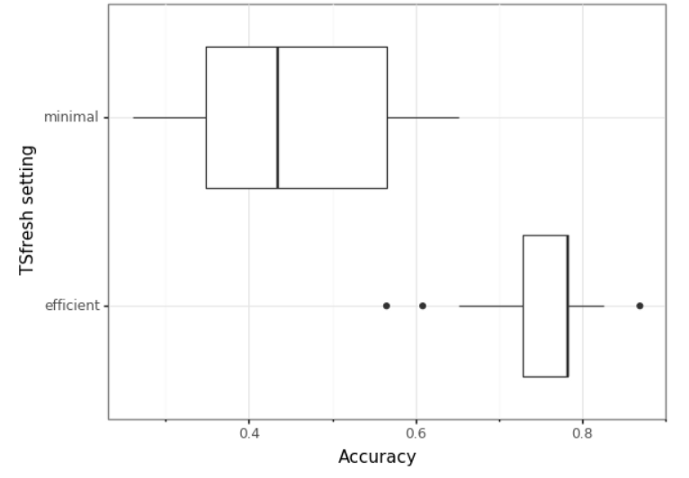
得到的箱线图清楚地表明,与基于最小特征的模型相比,有效tsfresh变量显示了更高的平均精度0.75,而不是0.4。这证实了我们的假设,我们将在本文的其余部分使用有效的特征。
通过交叉验证选择正则化强度
在使用正则化时,我们必须做出的一个主要选择是正则化的强度。在这里,我们使用交叉验证来测试C的一系列潜在值的准确性。
sklearn很方便地包含了一个用于逻辑回归分析的函数:LogisticRegressionCV。它本质上具有与LogisticRegression相同的接口,但是你可以传递一个潜在的C值列表来进行测试。
有关代码的详细信息,请参阅generate_drum_model.py,我们将结果从磁盘加载到此处以节省时间:
from sklearn.svm import l1_min_c
from joblib import dump, load
cs = l1_min_c(audio_tsfresh, all_labels, loss='log') * np.logspace(0, 7, 16)
cv_result = load('pkl/drum_logreg_cv.joblib')
注:我们使用l1_min_c来获得模型包含非零系数的最小c值。然后我们在上面乘上一个0到7之间的16个对数,这样得到16个潜在的C值。我没有一个很好的理由来解释这些数字。转换为α,并取log10,我们得到:
np.log10(1/(2*cs))

这其中包含一个很好的正则化强度范围,我们将在结果的解释中看到。
交叉验证选择了以下𝛼值:
np.log10(1/(2*cv_result.C_))
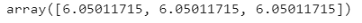
注意我们有三个值,每个子模型一个(kick-model, tom-model, snare-model)。在这里,我们看到,6左右的正则化强度被认为是最优的(C=4.5e-07)。
基于CV结果对模型的进一步解释
cv_result对象包含更多关于交叉验证的数据,而不是拟合的正则化强度。在这里,我们首先看看交叉验证模型中的系数,以及它们在不断变化的正则化强度下所遵循的路径。注意,我们使用helper_functions,py中的plot_coef_paths函数:
plot_coef_paths(cv_result, 'kick', audio_tsfresh) + theme(figure_size=(16,12))
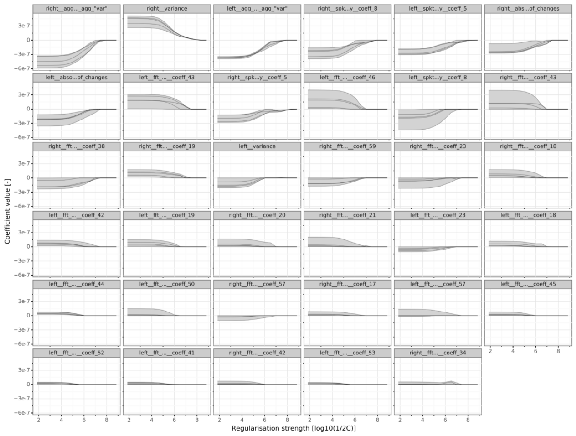
注:我们在图中看到5条线,因为默认情况下我们执行5折交叉验证。另外,我们重点研究了kick子模型。图中有以下有趣的观察结果:
-
增加正则化强度会减小系数的大小。这正是正则化应该做的,但是结果支持这一点是很好的。
-
增加的褶皱线减少了强度之间的变化。这符合正则化的目标:减少模型中的方差。然而,褶皱之间的变化仍然非常剧烈。
-
对于后面的系数,总的系数大小会下降。
-
对于交叉验证的正则化强度(6),相当多的系数从模型中消失。在tsfresh生成的327个潜在特征中,只有大约10个被选为最终模型。
-
许多有影响的变量是fft分量。这很直观,因为鼓样本之间的差异集中在特定频率(低音鼓->低频,圈套鼓->高频)。
这些观察结果描绘了这样一幅图景:正则化回归按预期工作,但肯定还有改进的余地。在这种情况下,我怀疑每种类型的鼓有25个样本是主要的限制因素。
除了看系数及其变化,我们还可以看看子模型的总体精度与正则化强度的关系。注意,我们使用helper_functions.py中的plot_reg_strength_vs_score,你可以在github上找到。
plot_reg_strength_vs_score(cv_result) + theme(figure_size=(10,5))
请注意,准确度覆盖的不是一条线而是一个区域,因为在交叉验证中,我们对每一次都有一个准确度分数。图中的观察结果:
-
在拟合的正则化强度(6->0.95)下,kick 模型总体表现最佳。
-
tom模型的性能最差,最小和最大精度都低。
-
性能峰值介于5–6之间,这与所选值一致。在强度较小的情况下,我怀疑模型中剩余的多余变量会产生太多的噪声,然后正则化会去掉太多的相关信息。
结论:正则回归模型的性能
基于交叉验证的准确度得分,我得出结论,我们在生成鼓声识别模型方面相当成功。尤其是底鼓很容易区别于其他两种类型的鼓。正则化回归也为模型增加了很多价值,降低了模型的整体方差。最后,tsfresh展示了从这些基于时间序列的数据集生成特征的巨大潜力。
改进模型的潜在途径有:
-
使用tsfresh生成更多潜在的输入特征。
-
使用更多的鼓样本作为模型的输入
原文链接:towardsdatascience.com/expanding-y…
欢迎关注磐创AI博客站: panchuang.net/
sklearn机器学习中文官方文档: sklearn123.com/
欢迎关注磐创博客资源汇总站: docs.panchuang.net/
